Note: This functionality is available for Advanced users only.
In early 2021, we rolled out the much anticipated second installment of enhancements to the Nextpoint import experience with the introduction of a load file mapper for produced data imports. This new and improved workflow will accommodate most produced data imports with a load file, but we understand some users may still want to utilize the workflow they were previously used to. We refer to this as a Manual Import - one in which you modify your load file before uploading to the File Room and do not use the load file mapper.
In addition to serving existing workflows, this Manual Import Type is helpful in the event you have data for import which has already been processed. In particular, we see this most often with a native production import which already has attachments extracted from their parent emails. This approach allows you to choose to disable child processing which prevents attachments from extracting from their parent emails a second time.
All steps outlined below based on the assumption of a ranged image import. See below for a breakdown of the typical format for such an import:
What Does a Ranged Image Import Look Like?
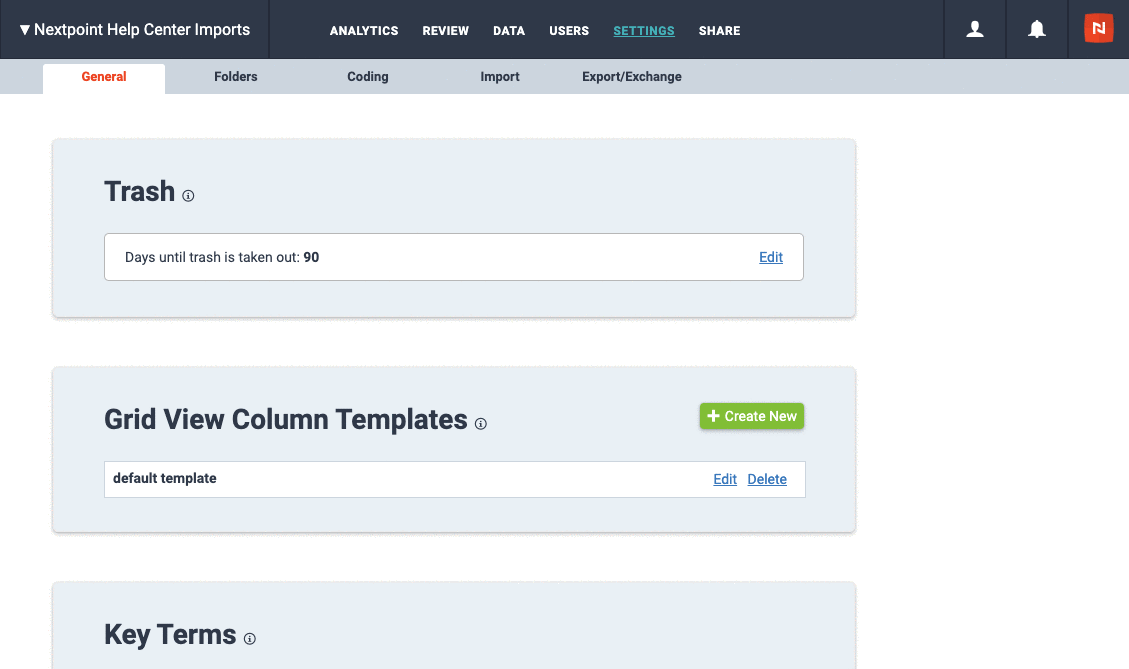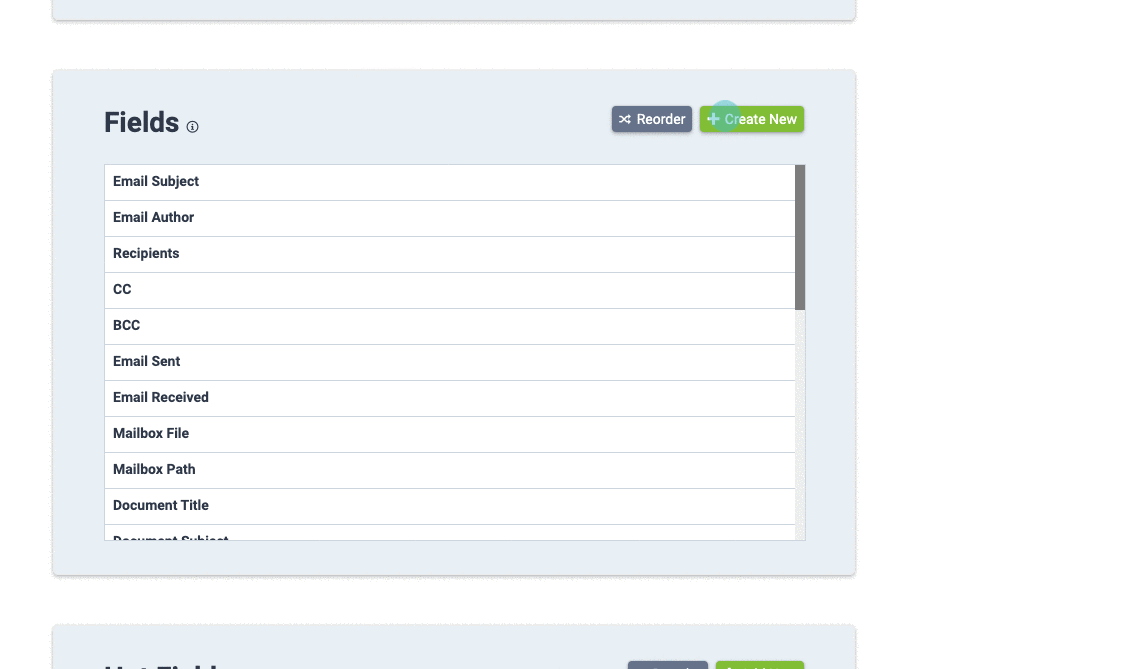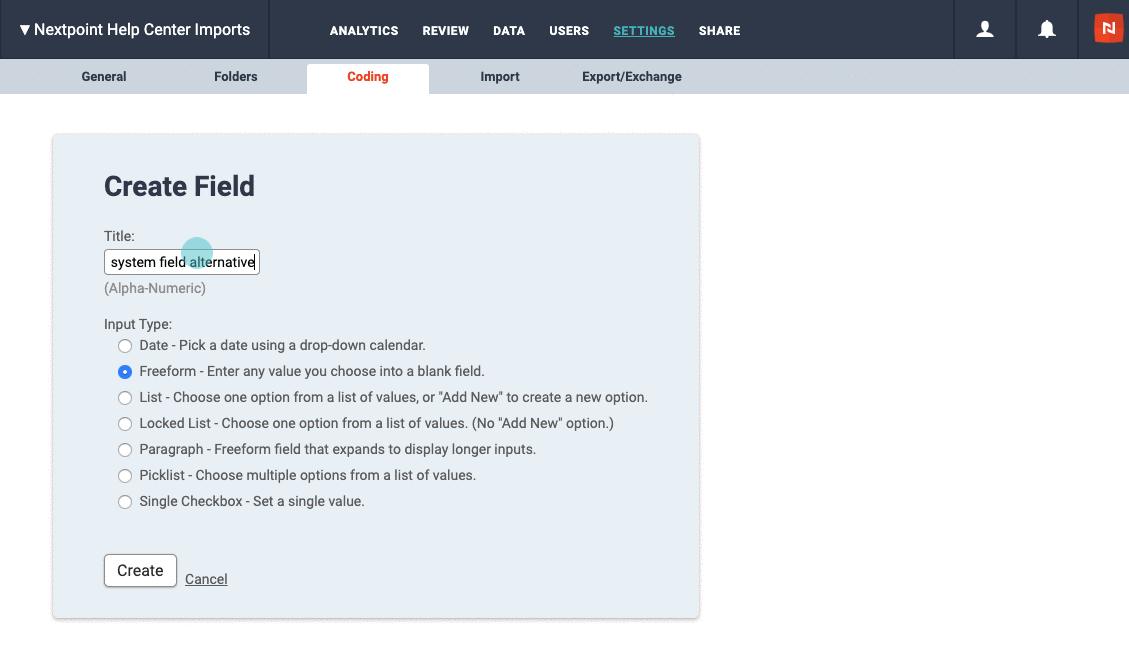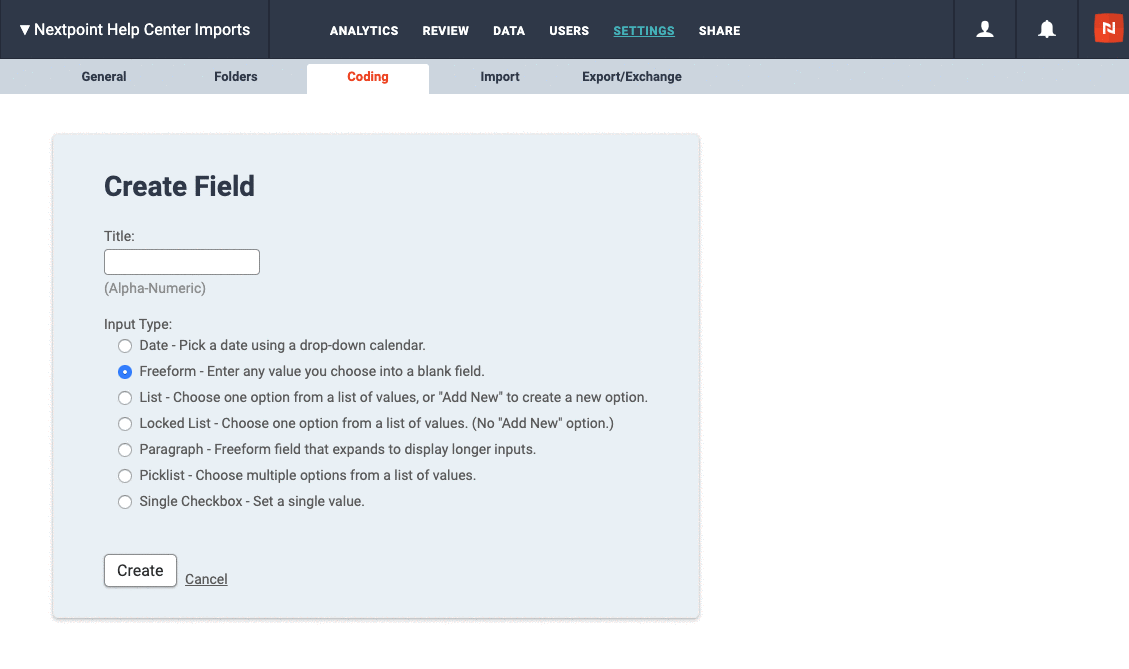
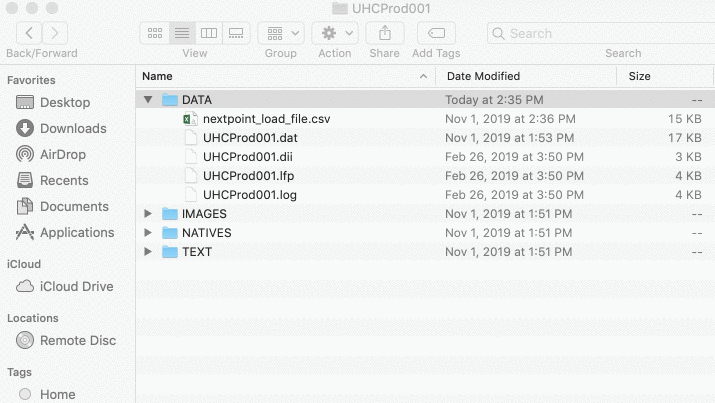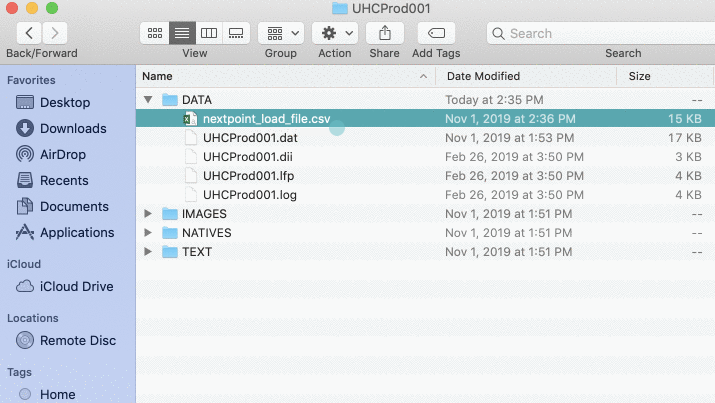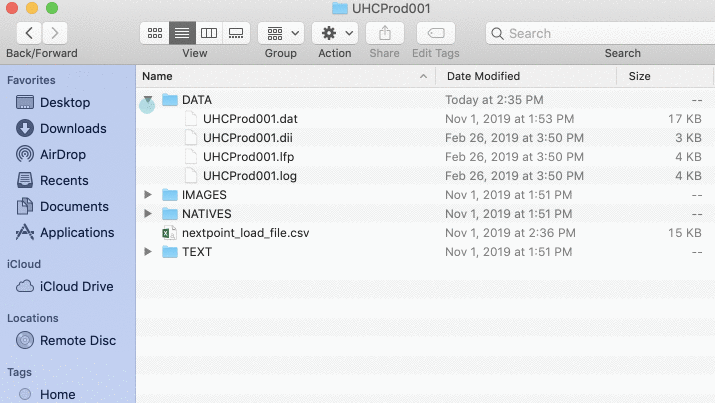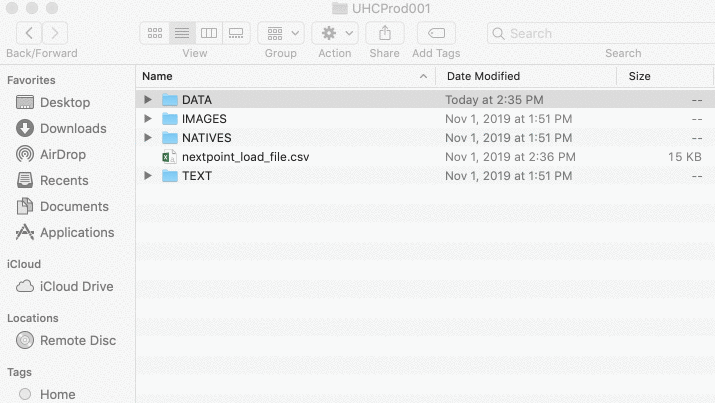
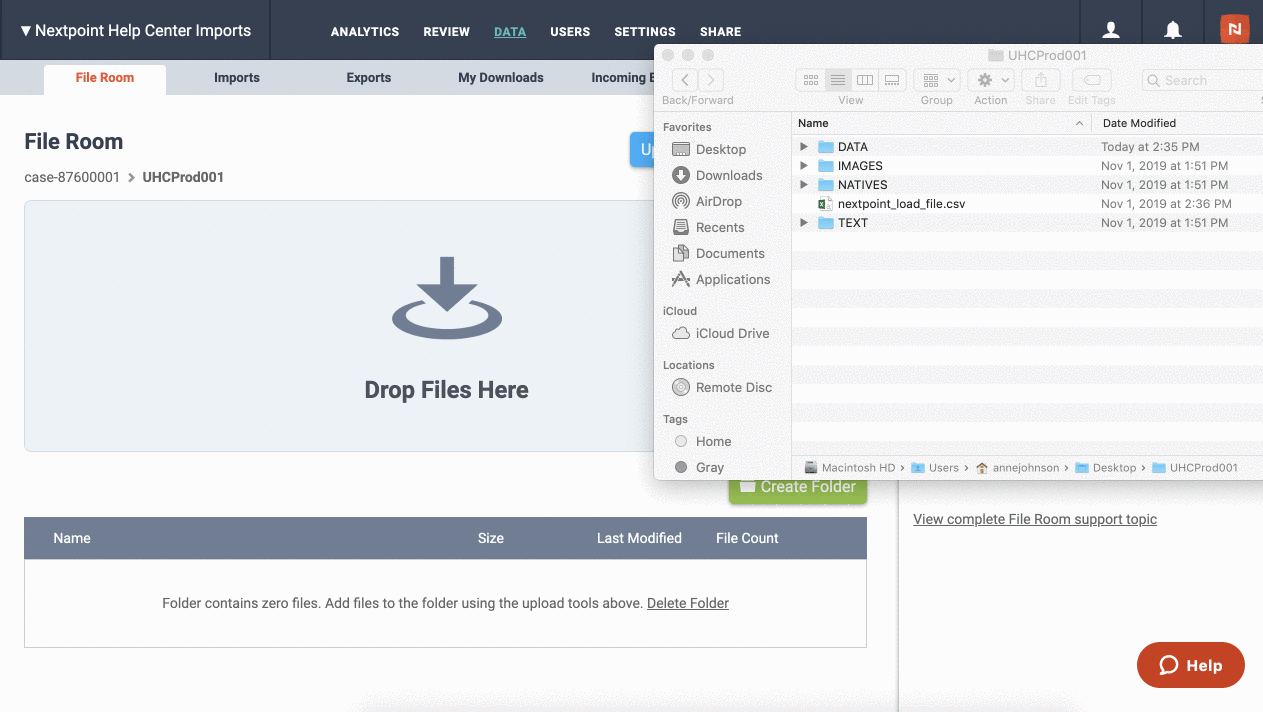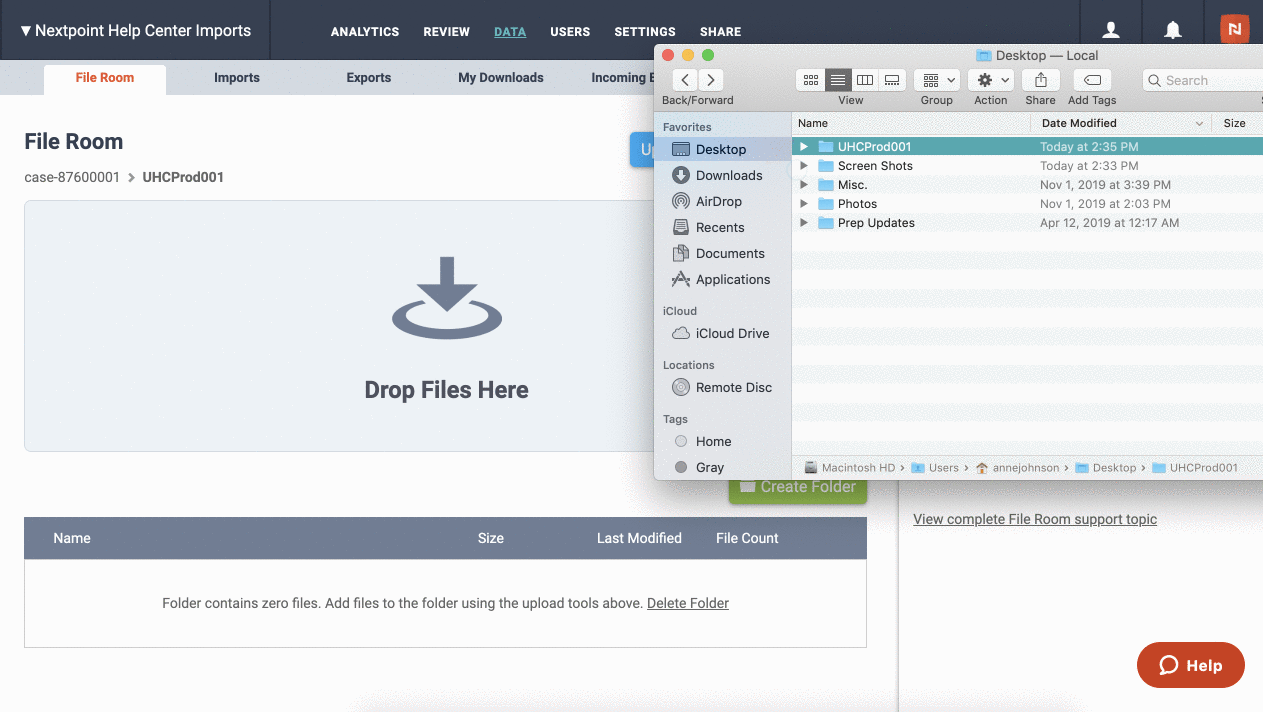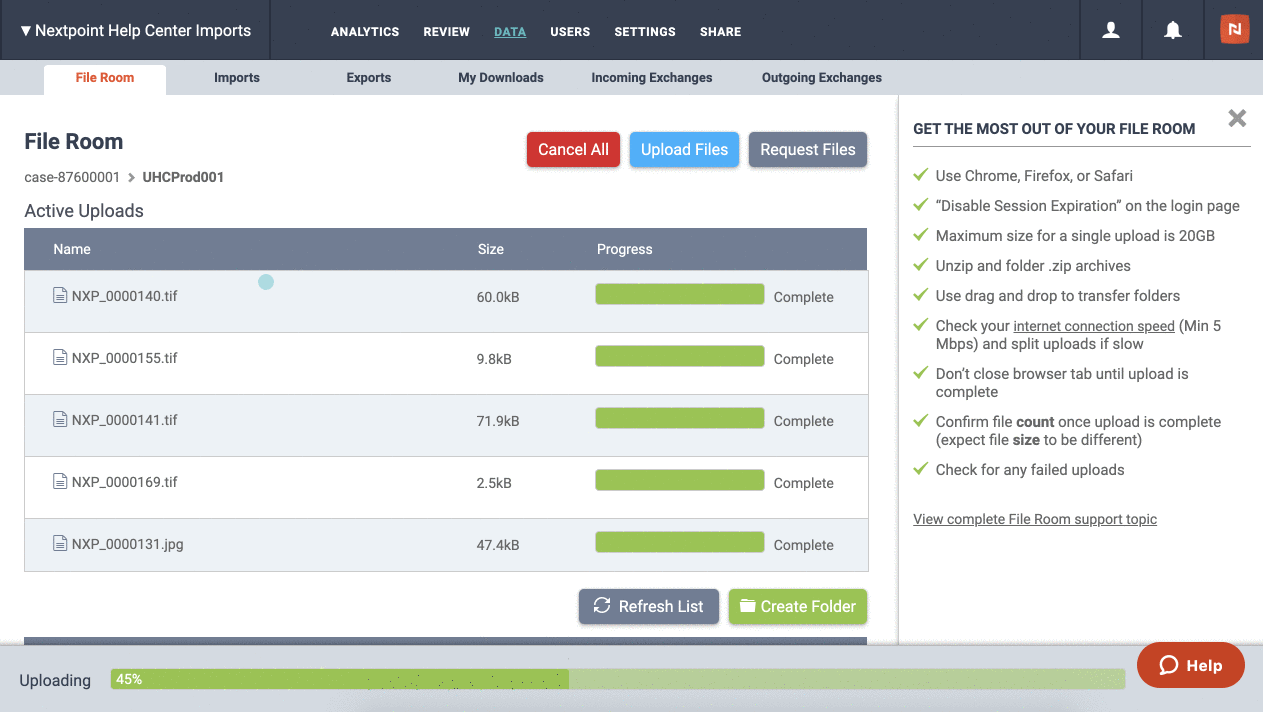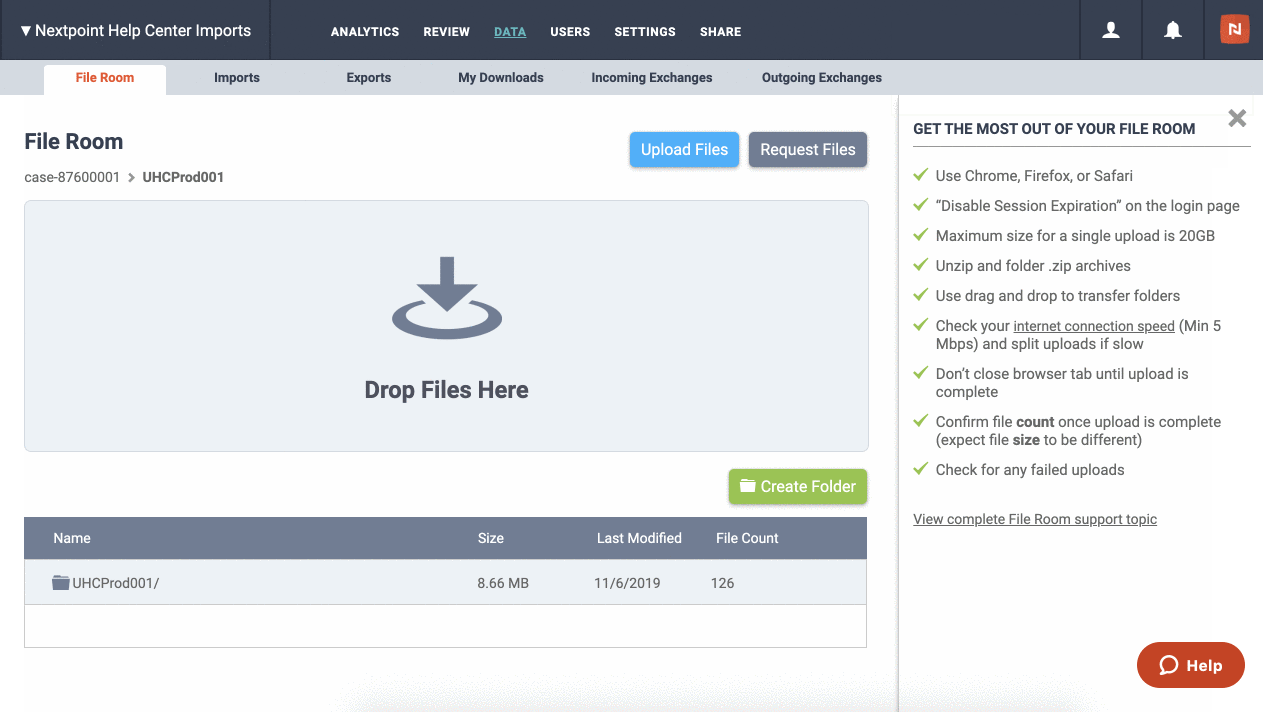
Your produced data set will contain up to 4 folders. At the very least, this type of data set must contain an "Images" or "IMAGES" folder):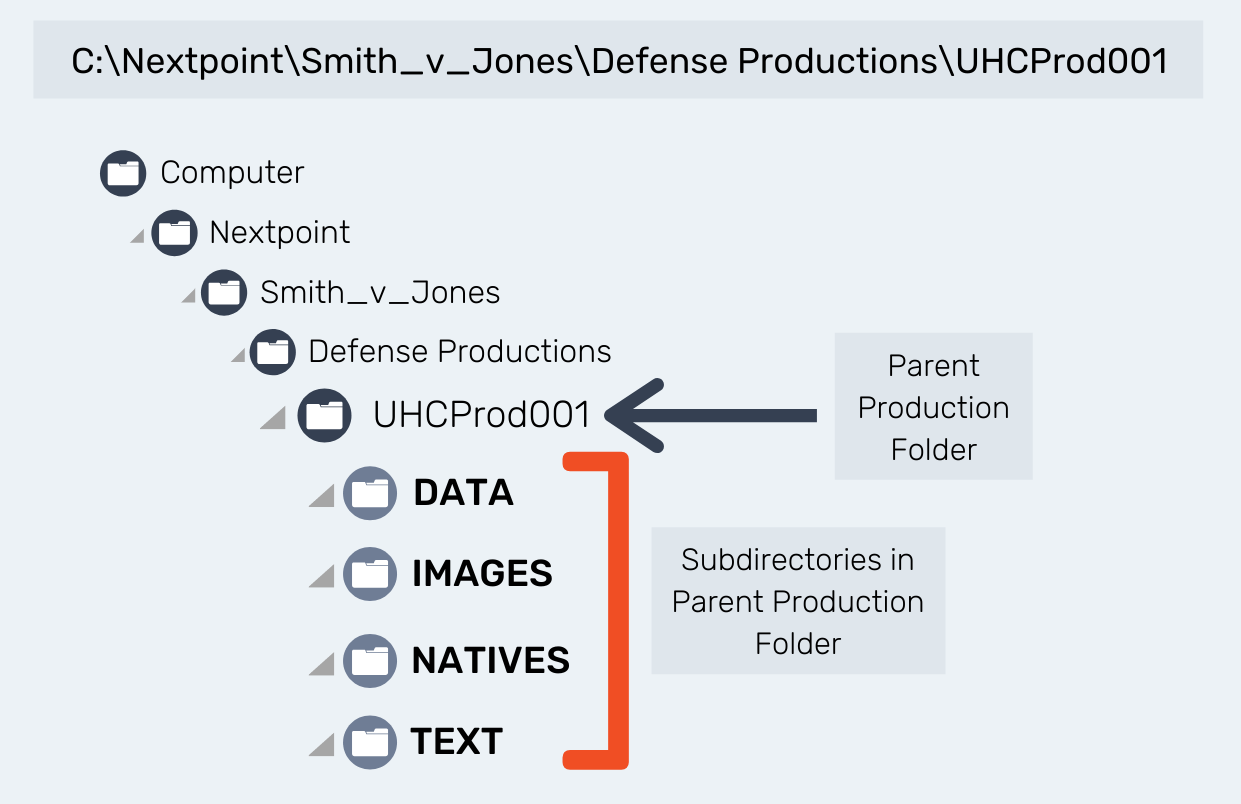
IMAGES - This folder contains the document pages, each a one-page image file. Image file pages will be in the .tif or .jpg format, and the files will be named by their Bates numbers.
TEXT - This folder contains the OCR text information, and can be either one text file per page, or one text file per document. If included, the OCR text files will be named by the corresponding Bates start numbers of the document they represent.
NATIVES - This folder contains any native files that accompany each document. If included, the Native files will be named by the corresponding Bates start numbers of the document they represent.
DATA - This folder contains load files associated with your data set. All information contained within the load file serves as an instruction manual for Nextpoint during import so the correct IMAGES, NATIVES, and TEXT files are combined to create unique documents and those documents can be viewed, searched, and filtered.
These load files will, at the minimum, contain document boundary information outlining which image files should be extracted from the aforementioned IMAGES directory and combined to create unique documents during import. Additionally, load files will oftentimes include data about the documents (Author, Recipients, Bates range, etc..) and have the paths to text and native files within the TEXT and NATIVES directories.
Below is what a graphic representation of a what a common ranged image data set looks like (when it is expanded):
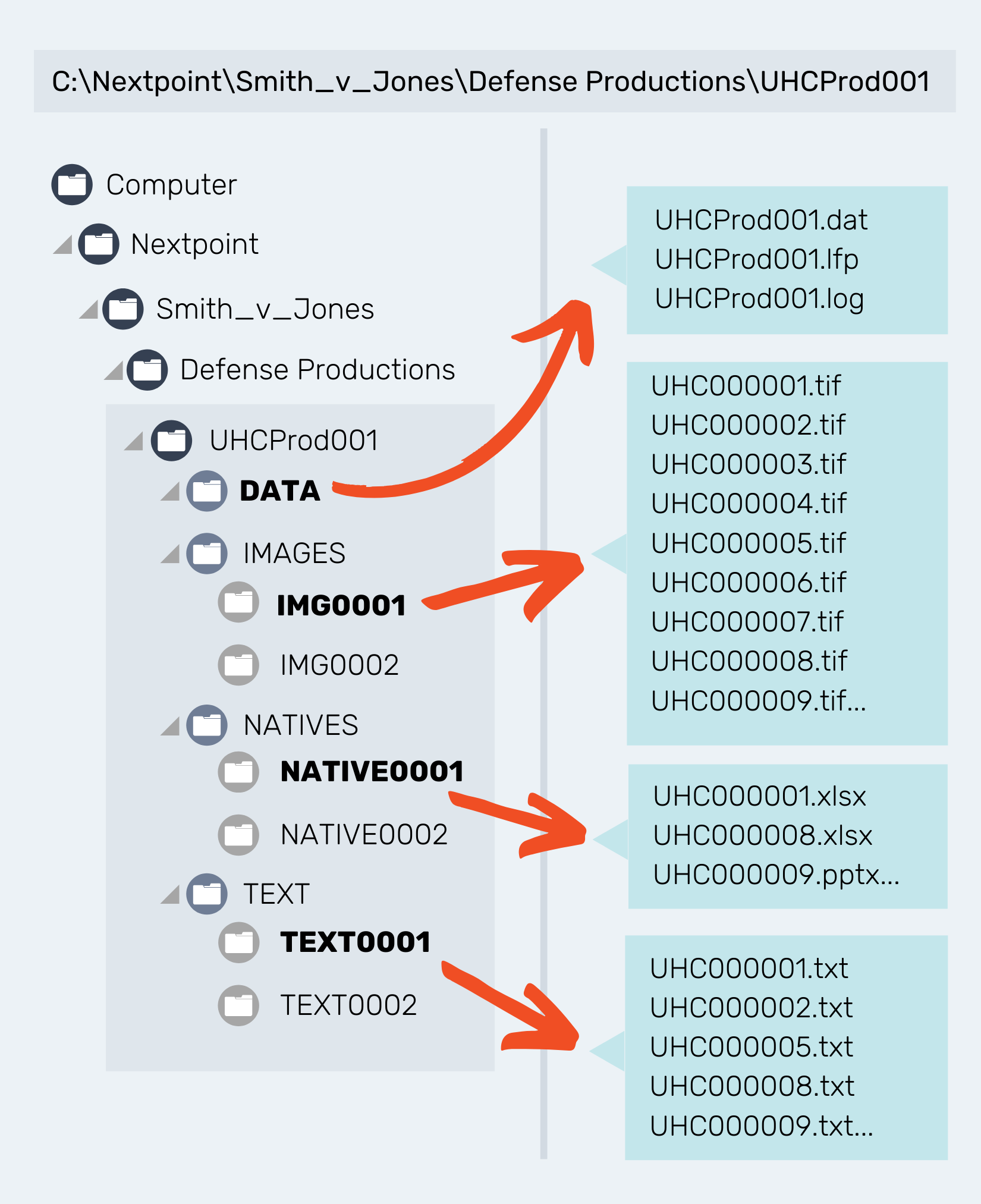
Produced Data Import Instructions
The following steps have been strategically organized to help guide you through the import of produced data using the Manual Import Type selection. We recommend navigating the instructions one step at a time.
It is also recommended you review these required considerations for produced data imports prior to proceeding with the below Produced Data Import Instructions.
Open your production folder and review the subdirectories for the following specifications:
- DATA: Check for a .CSV and/or .DAT load files. If you have a .DAT, you must convert this file type to a more user-friendly .CSV format in Step 2. Additional file types such as .lfp, .log, .opt, may be discarded for purposes of these instructions.
- IMAGES: Check for single-page tiffs/jpgs named by their Bates number. In some cases, the image files are provided as PDFs named by their Bates start and that is acceptable.
- TEXT: Check for per-document text files. These are named by the Bates start of each document.
- NATIVES: Check for any native file types which have been provided. These are named by the Bates start of the document. Oftentimes Excel, Powerpoint, and other file types which do not image well (or at all).
A reminder of what you should anticipate seeing in a ranged image import:
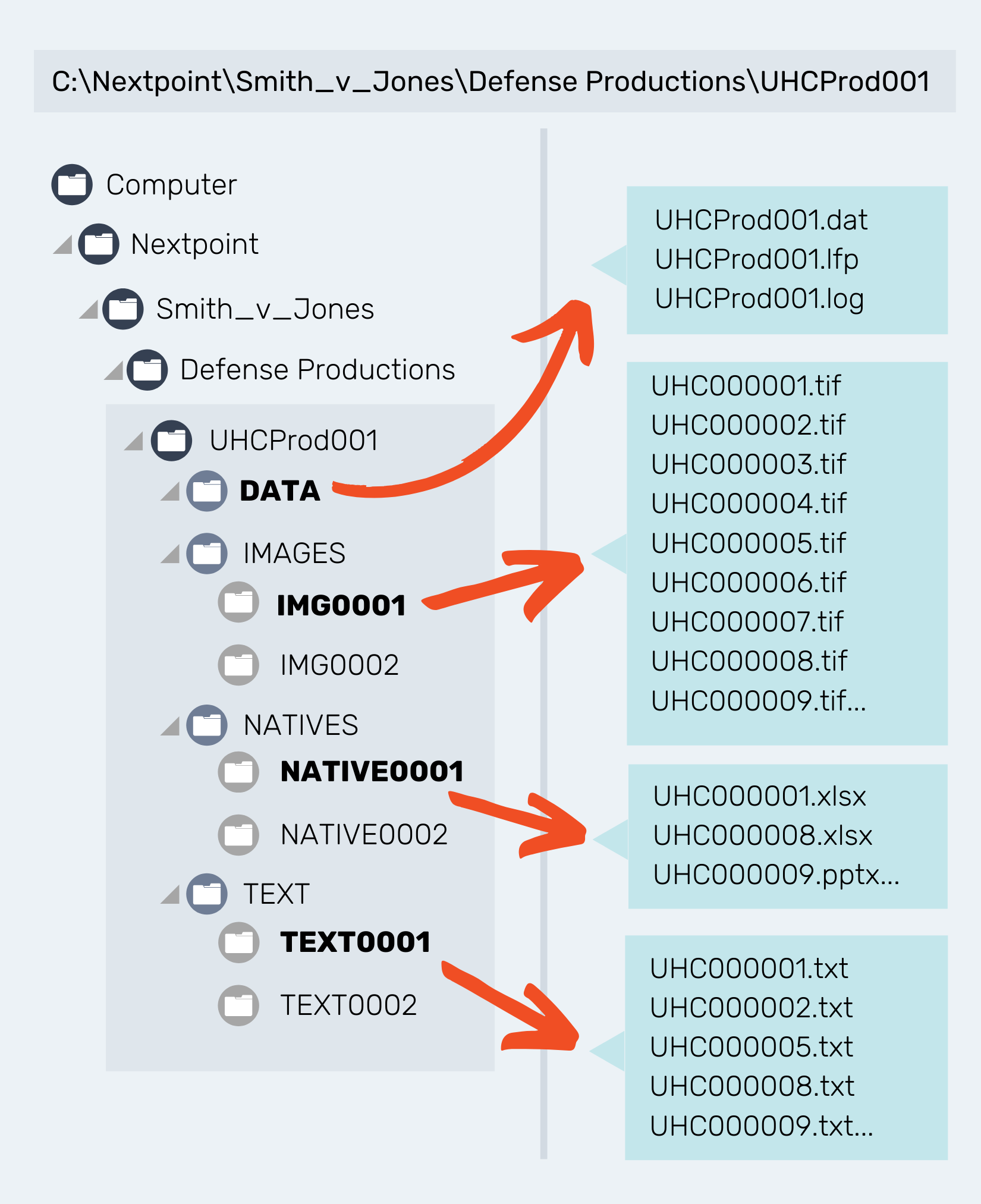
FAQ: My TEXT (.txt) files are located in my IMAGES folder. What do I do?
If your text (.txt) files are not in a separate TEXT folder, that is typically OK. You will need to supplement a field in your load file titled image_extension. We further explain how to add this field when you get to Step 3 | Load File Configuration --> Document Boundaries.
For successful import to Nextpoint, load files must be saved in a CSV (comma-separated value) format.
If you located a .DAT in your DATA folder in Step 1, you must first convert the file to a .CSV before proceeding. Not only is it required for the Manual Import Type in Nextpoint, but making the conversion from .DAT .CSV allows you to more easily view your load file and make necessary modifications (in Excel). VS
VS 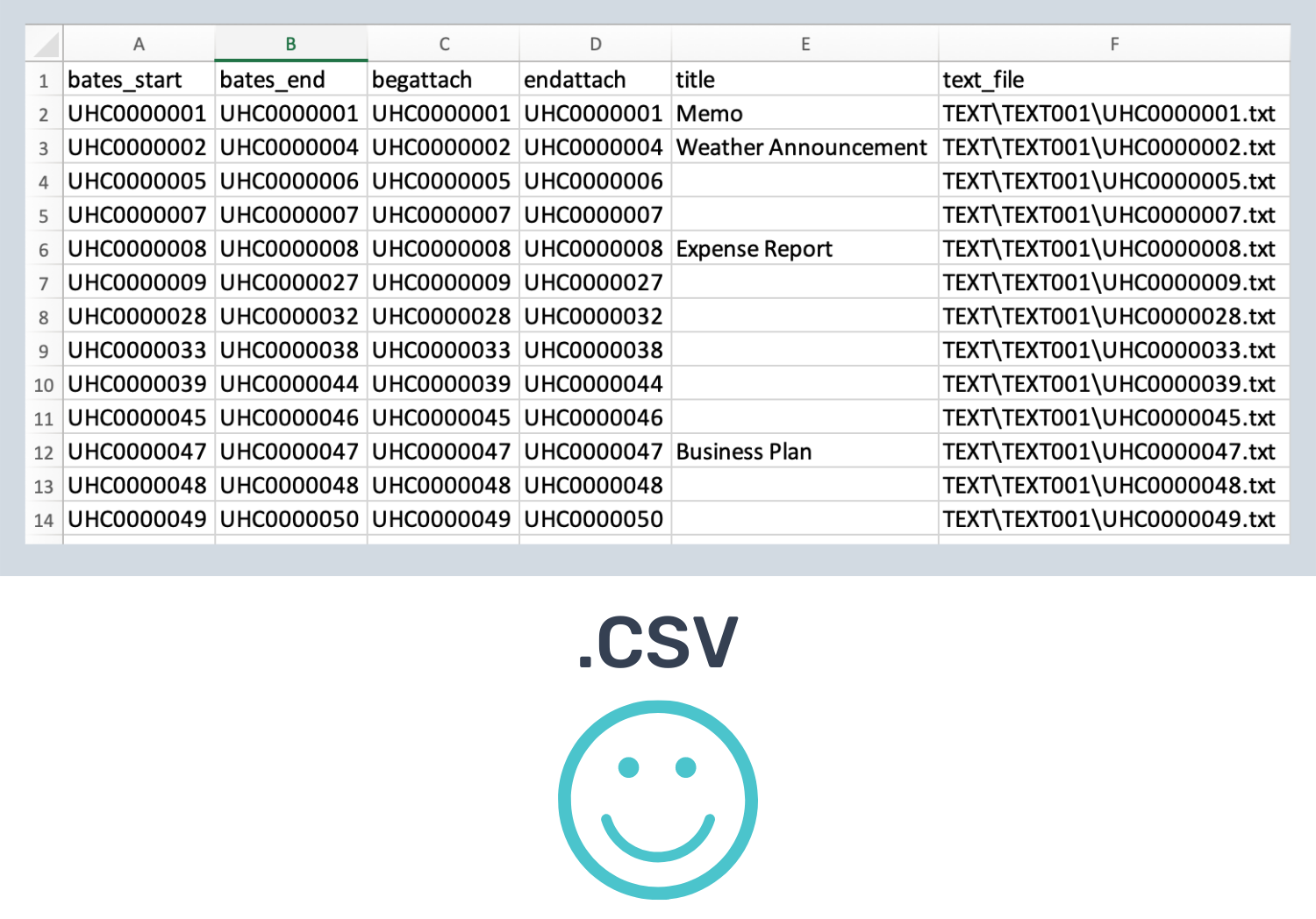
Steps to convert a .DAT to .CSV:
- Open your .DAT file in a text editor such as TextPad or Sublime Text (this is the application preferred by Nextpoint Data Analysts).
To open, right click on the .DAT file Select "Open With" click on the text editor program you would like to use.
- Once opened in your text editor, the values in your .DAT file will likely be separated by the symbols þ□þ (thorn, □ (ASCII 20), and another thorn). So, the text displayed resembles this:
þProdBegþ□þProdEndþ□þBegAttachþ□þENDAttachþ□þCustodiansþ
If using Sublime text, your beginning state may look like this:
þProdBegþ<0x14>þProdEndþ<0x14>þBegAttachþ<0x14>þENDAttachþ - Using the functions in TextPad or Sublime, you must complete a find and replace on the aforementioned characters to convert the load file format. Use the following sequence:
- Find-replace all " (quote) with "" (double quote) - This will ensure your line breaks remain consistent.
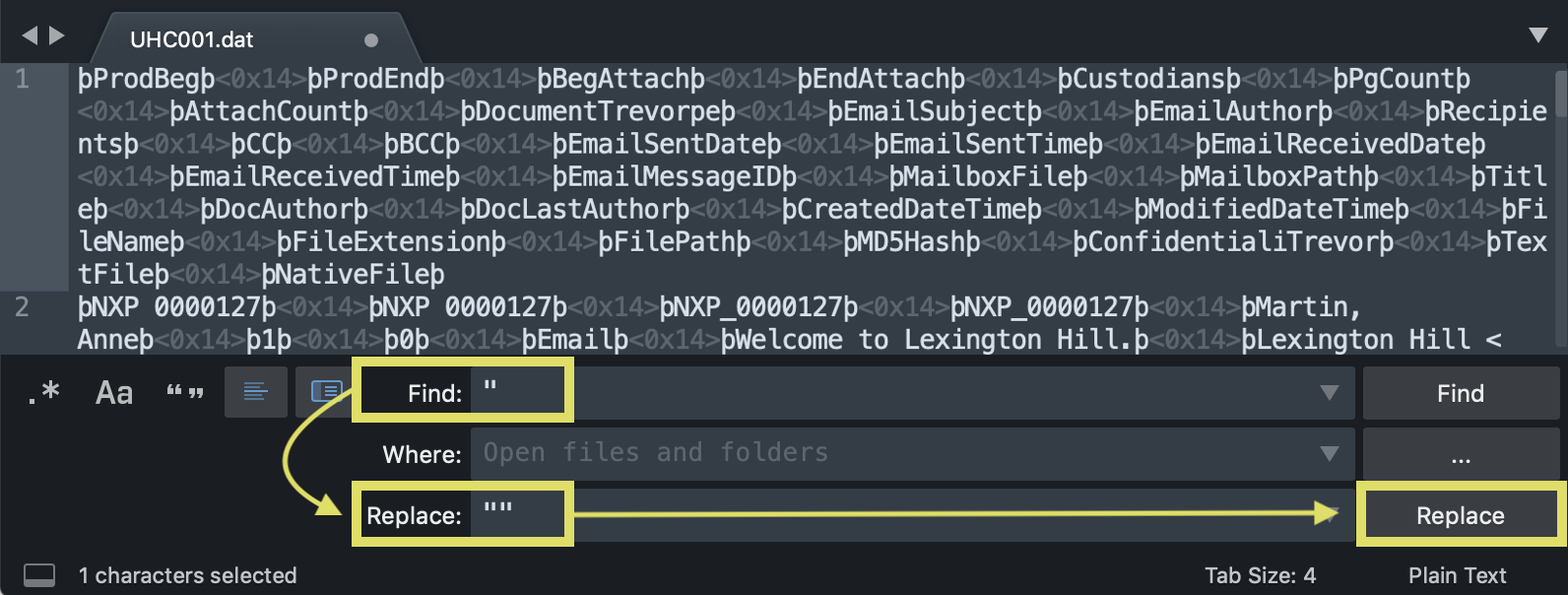
- Find-replace all þ (thorn) with " (quote)
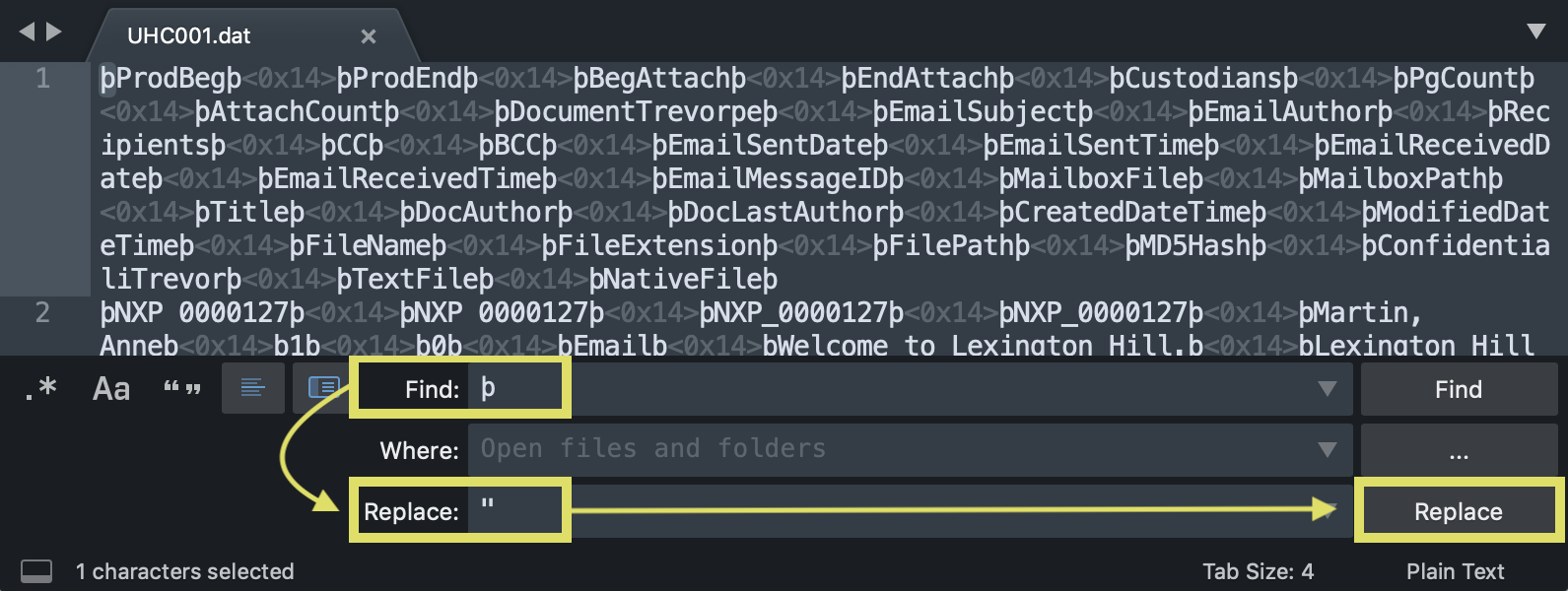
- Find-replace all □ (ASCII 20) with , (comma) - □ may read as <0x14> if working in Sublime Text.

- Find-replace all " (quote) with "" (double quote) - This will ensure your line breaks remain consistent.
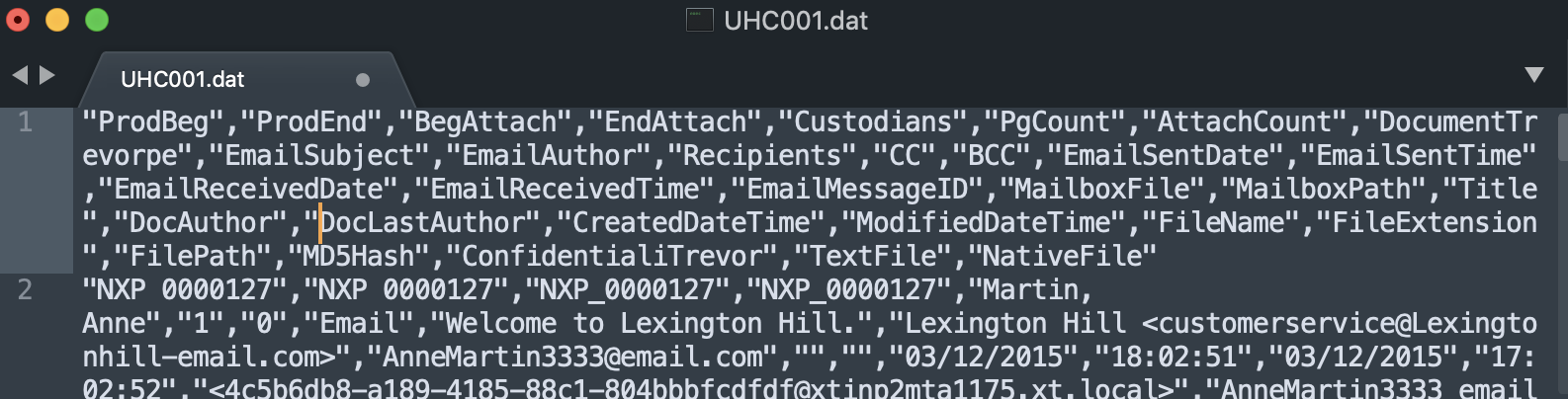
- The find and replace actions you take above in Step 3 will result in all values being now separated by "," (quote comma quote, or in other words, comma separated values / CSV). The text displayed should resemble this:
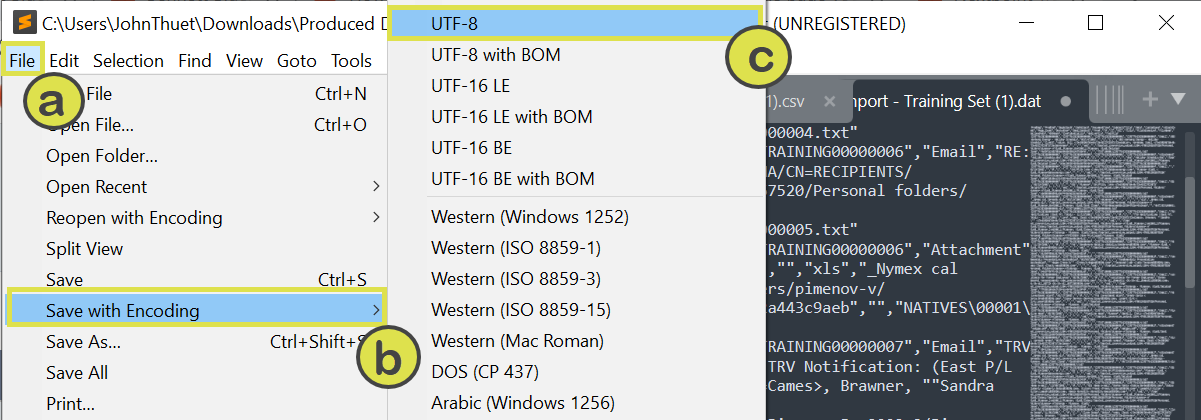
- Though it is often not necessary, at times DAT files are not provided in UTF-8 format. Therefore, it is best practice to save the file with UTF-8 encoding. Select "File" > "Save with Encoding" > "UTF-8".
- Save your file as: nextpoint_load_file.csv.

- Locate your nextpoint_load_file.csv in your production folder and open the file in Excel. Your values will be separated into columns, and much easier to work with moving forward.

Prefer a video tutorial on converting your load file from .DAT to .CSV? Watch here >>
Troubleshooting: "My find-replace is not working correctly."
Some clients using Textpad or Notepad have had trouble in the past with certain characters being unexplainably replaced during this process, thus altering the desired results of their ending CSV (e.g. "" replacing the character sequence of "th" ). If you notice nuances in your resulting CSV, some users have found Sublime Text to be a helpful text editor alternative.
Now, you will make modifications to your .CSV load file AND Nextpoint database fields to ensure all information in your load file has somewhere to go when imported into your Nextpoint database.
Once your load file is converted in Step 2, open your resulting .CSV in Excel, if you have not already. Each row in your load file (spreadsheet) contains the information for one document. 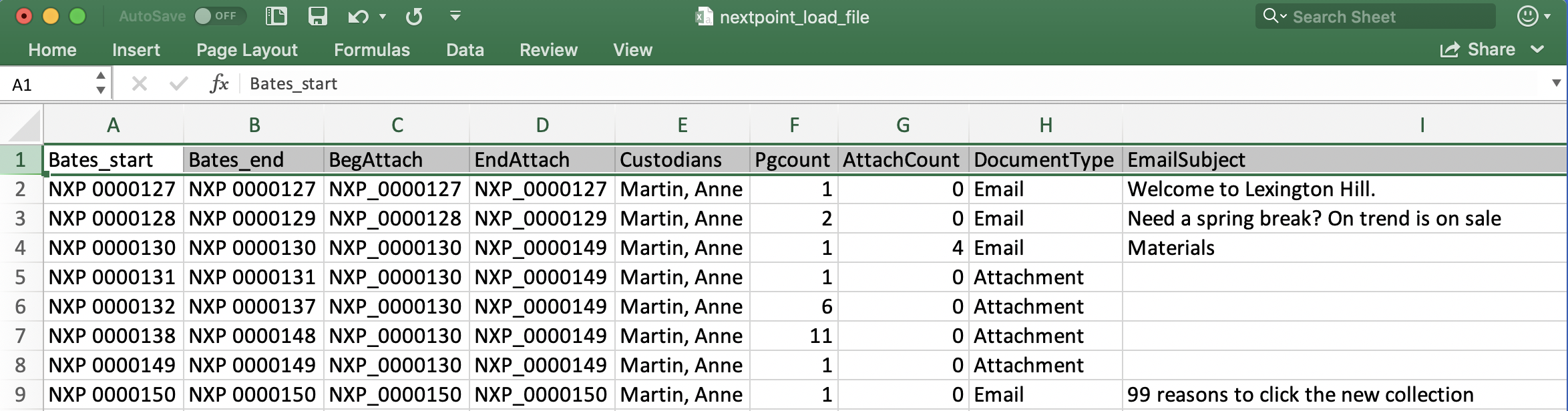
DOCUMENT BOUNDARIES
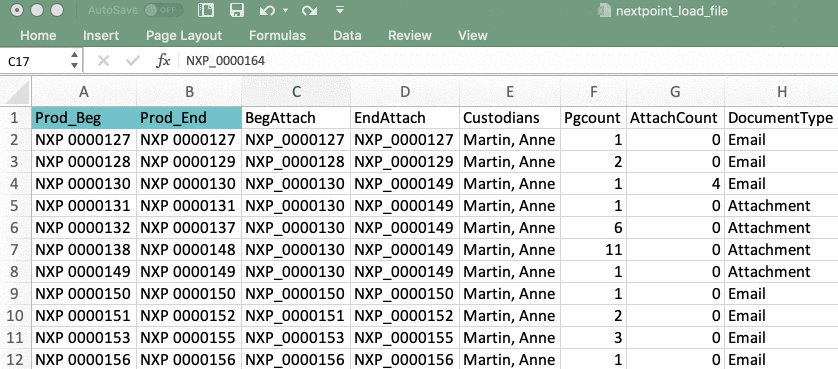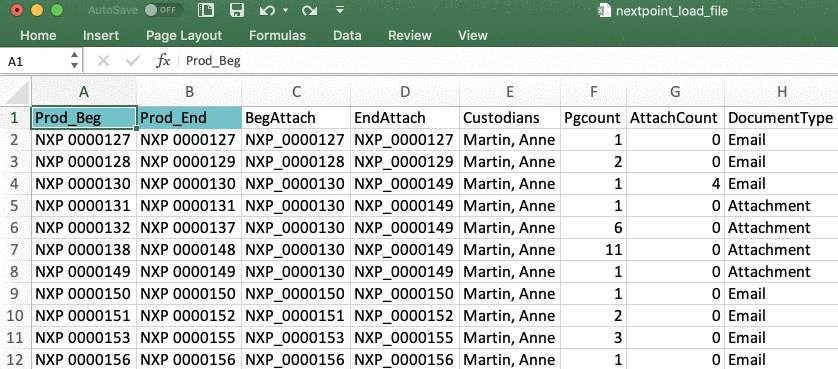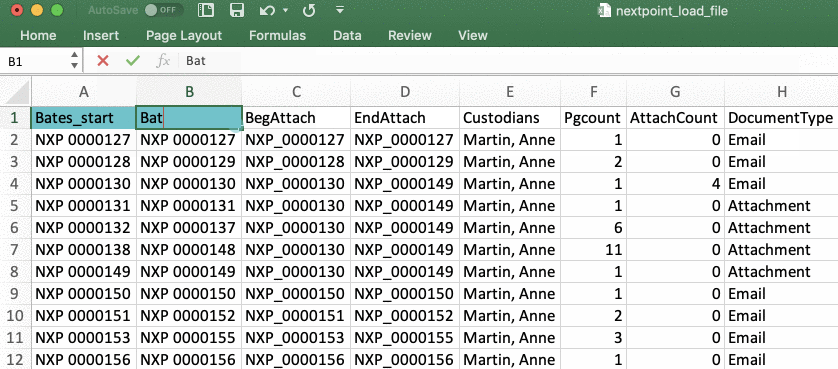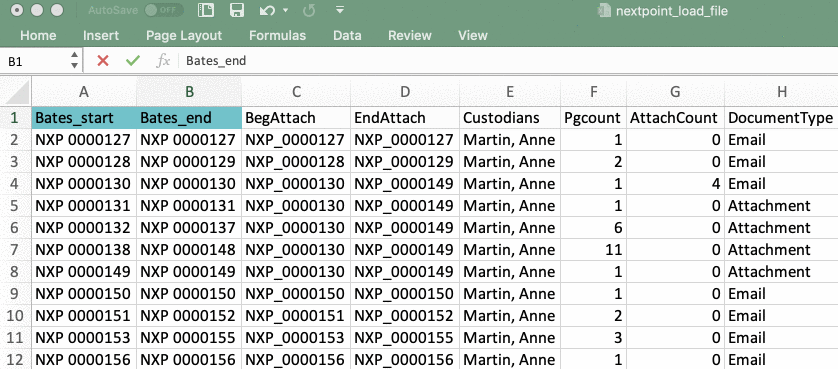
- In your load file, review the first two columns to confirm Bates_start and Bates_end or a general control number is present (e.g. Bates_begin/Bates_end OR prod_beg/prod_end)
- These beginning and ending numbers will identify which ranges of single page tiff/jpgs should be pulled from the IMAGES folder and combined to create individual documents.
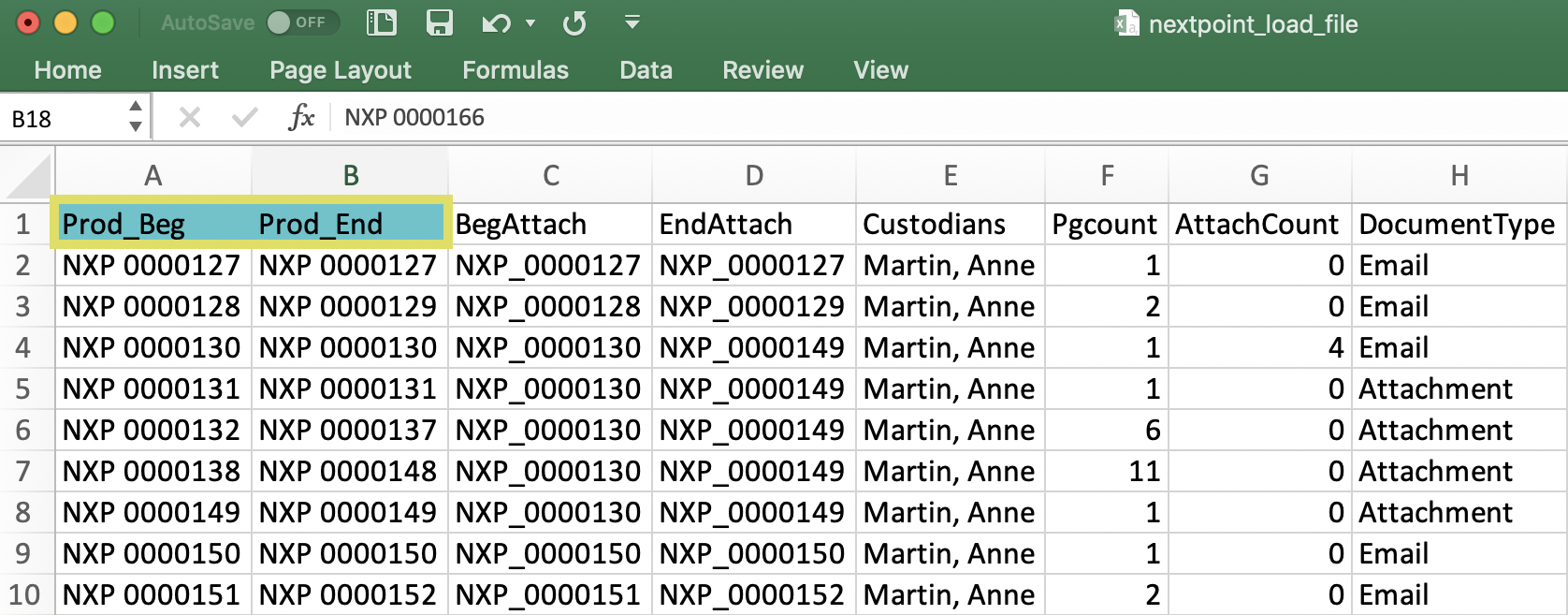
- These beginning and ending numbers will identify which ranges of single page tiff/jpgs should be pulled from the IMAGES folder and combined to create individual documents.
- If these two columns are named something other than Bates_start and Bates_end, you must rename these columns in your load file to Bates_start and Bates_end in order for your import to be successful. *Capitalization and underscores (vs. a space) do not matter.
If your Image files were provided as PDF's named by their Bates start in Step 1
If you have singular images for documents, such as a PDF (likely named by Bates start), you must add a column to your load file titled image_file. After you add the image_file column to your load file, you must then populate the cells below with the appropriate files' relative path information.
Read more here on how to populate the image_file column.
FAMILY RELATIONSHIPS
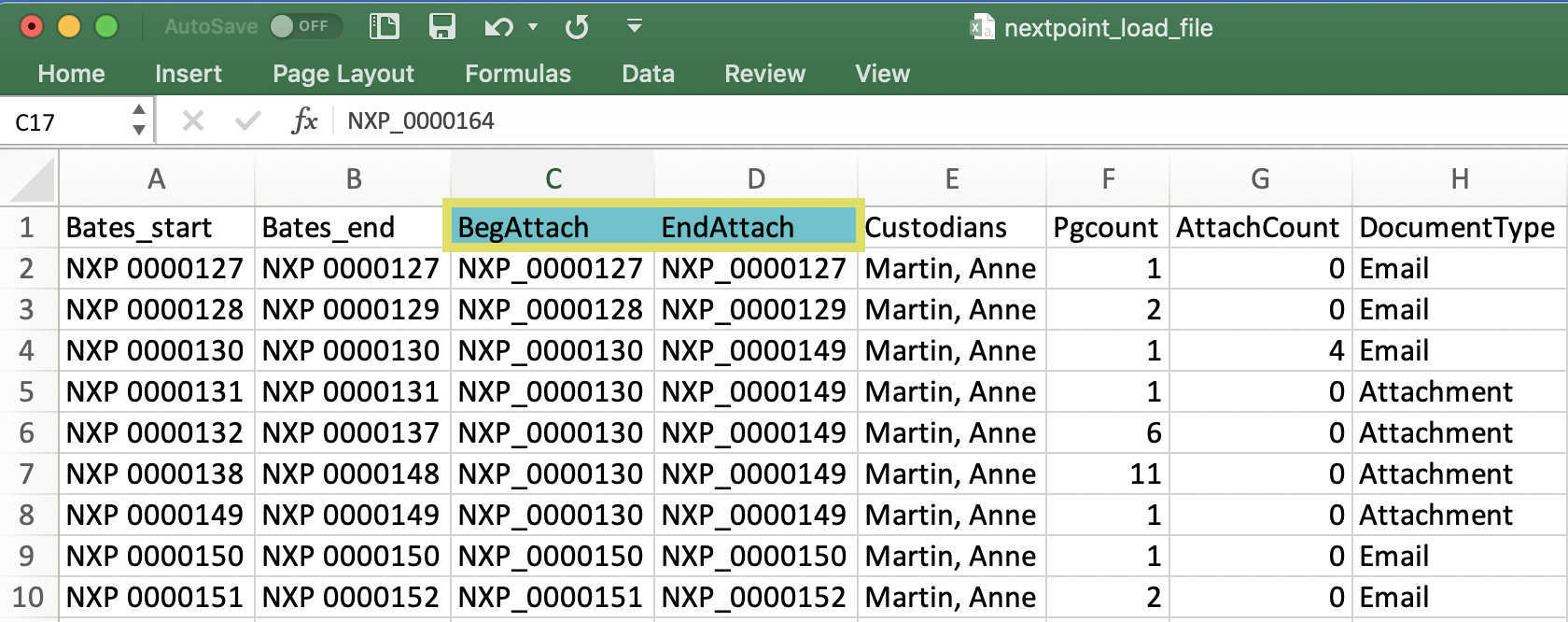
- In your load file, review your column headers to confirm Begattach and Endattach column headers are present. Sometimes these are titled production_begin and production_end, etc...
- These beginning and ending attachment numbers are vital to establishing email family relationships after your import is complete.
- Establishing these visual relationships after import is referred to as Family Linking and is further covered below in step 7.
- In your load file, if named anything other than begattach and endattach (e.g. prod_begin/end, production_beg_attach/production_end_attach, etc..), you must rename these columns to Begattach and Endattach in order for your import to be successful. *Capitalization and underscores (vs. a space) do not matter.
- In your Nextpoint Discovery database, if begattach and endattach fields are not present under Settings Coding Fields, then you must add begattach and endattach as Freeform fields.

- Importing to a Litigation database? You can add these fields under MORE Settings Coding Fields.
If your text (.txt) files were contained in your IMAGES folder in Step 1
If your image and text files are contained within the same folder (most oftentimes, IMAGES), you must add a column header in your load file titled image_extension and add the value tif|tiff|jpg|jpeg in all of the rows. Adding explicit file extensions for images will limit what sorts of files Nextpoint should consider as potential page images (and keep it from mistaking text files for images).
METADATA FIELDS
Once your document boundaries and family relationships are verified in the steps above, the next step is to verify the metadata fields in your load file. It is recommended you address the remaining load file fields in the following order:
- DEFAULT FIELDS
- First, see this list of Default Fields and Document Attributes, Exhibit A ("Exhibit A"). Fields on this list already exist in each Nextpoint database.
- If a column header in your load file matches, or is similar to, a field listed in Exhibit A, you must rename your load file header to match the field name from Exhibit A.
IMPORTANT: Your load file column header must exactly match the field name in Default Fields and Document Attributes, Exhibit A in order for your import to be successful.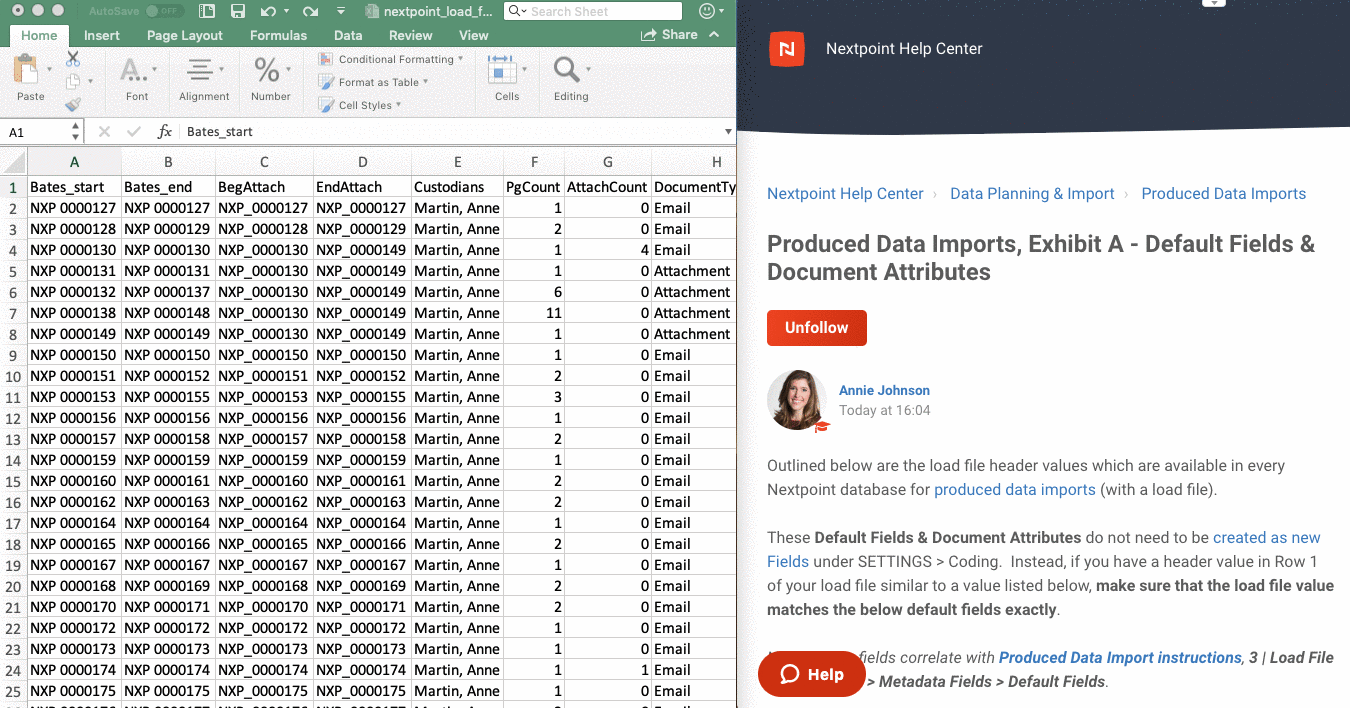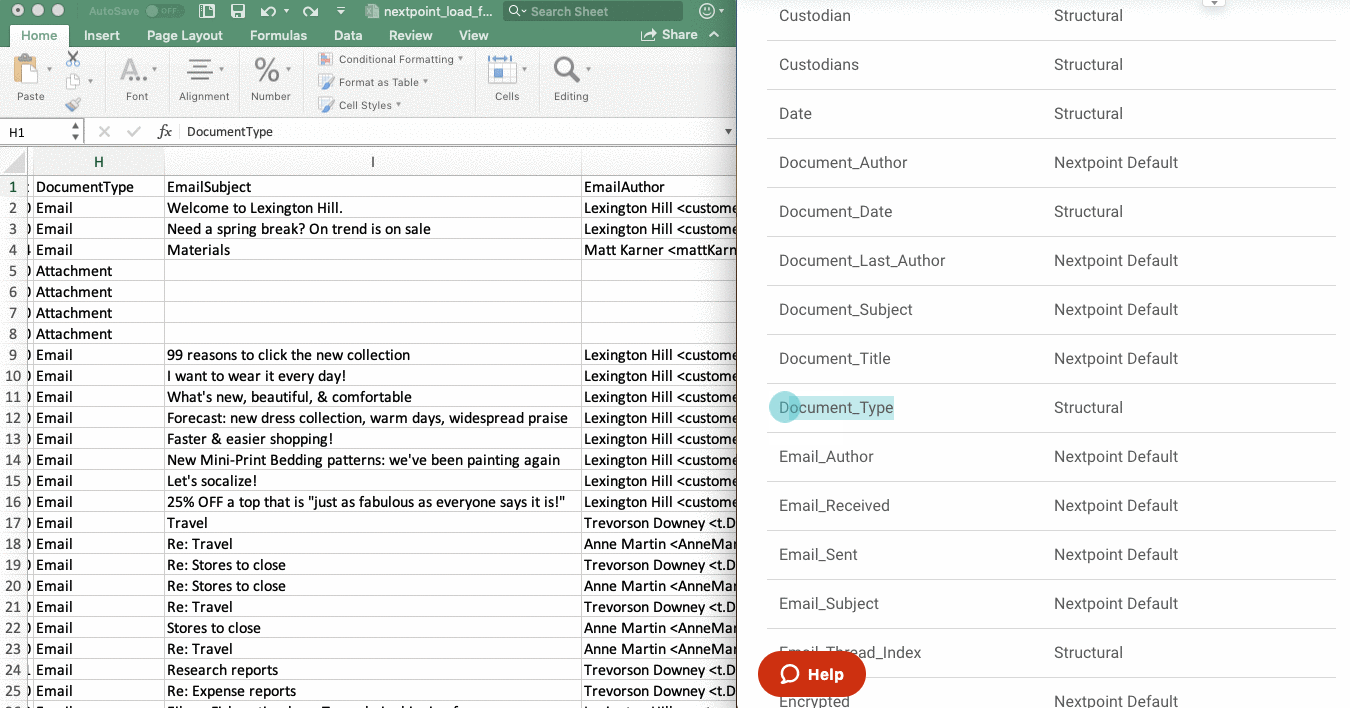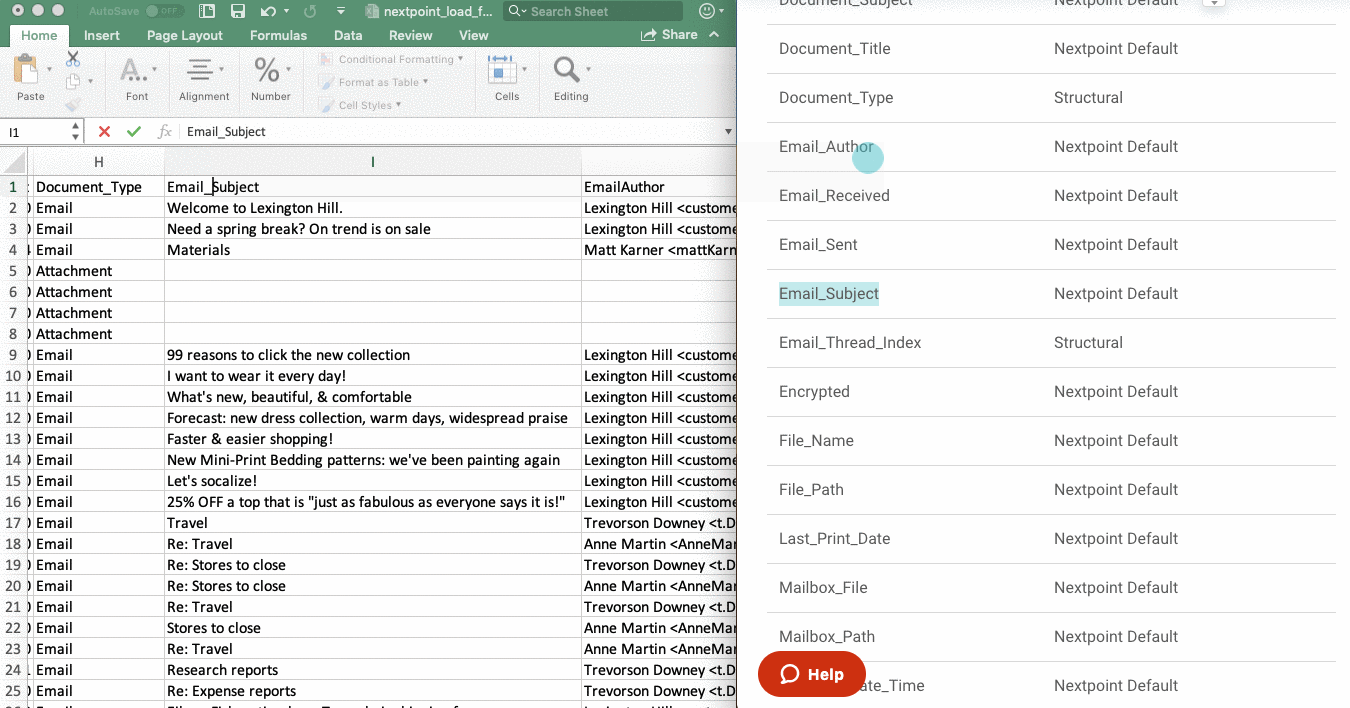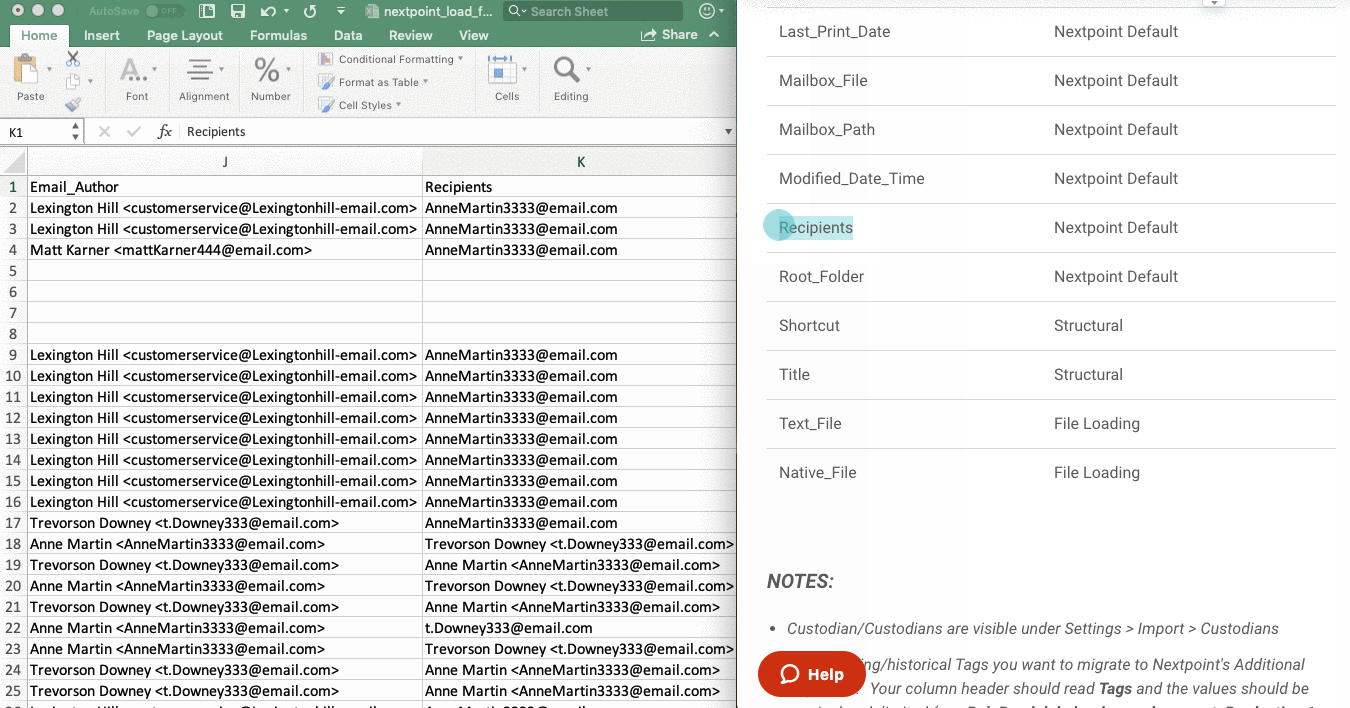
FAQ re: Default Fields
Q: I'm concerned if I use a header in my load file that is similar to, but not exactly the same, as a Default Field, I will mess up my import.
A: Don't worry, you will not "break" the import! Sometimes, it may be necessary to create similar fields to what is existing, and that is OK. For example, Nextpoint has a default Email_Sent field which incorporates the date AND time an email was sent. If you have Email_Sent_Date and Email_Sent_Time in your load file, it is perfectly fine to keep your load file fields named as such. However, if you do this, please make sure to set up the corresponding field in your Nextpoint Discovery database by navigating to Settings Coding Fields Create New Select Freeform Field enter the field name click "Create". This gives your load file data somewhere to go in Nextpoint once imported.
- PROTECTED SYSTEM FIELDS
- Next, see this list of Protected System Fields, Exhibit B ("Exhibit B"). Data cannot be imported into any of these fields because they are generated by the Nextpoint application.
- If a column header in your load file matches a field listed in Exhibit B, you must rename the fields in your load file to something different AND ALSO set up a corresponding field in your database.
- Renaming the field in your load file eliminates the use of a protected system field, and setting up the corresponding field in your database gives the information from your load file "somewhere to go" when your load file is ultimately imported into Nextpoint.
- Suggestions for what to rename the field in your load file (and subsequently add to your database) are provided in parentheses next to each field in Exhibit B.
RENAME FIELD IN YOUR LOAD FILE TO SOMETHING OTHER THAN PROTECTED SYSTEM FIELD: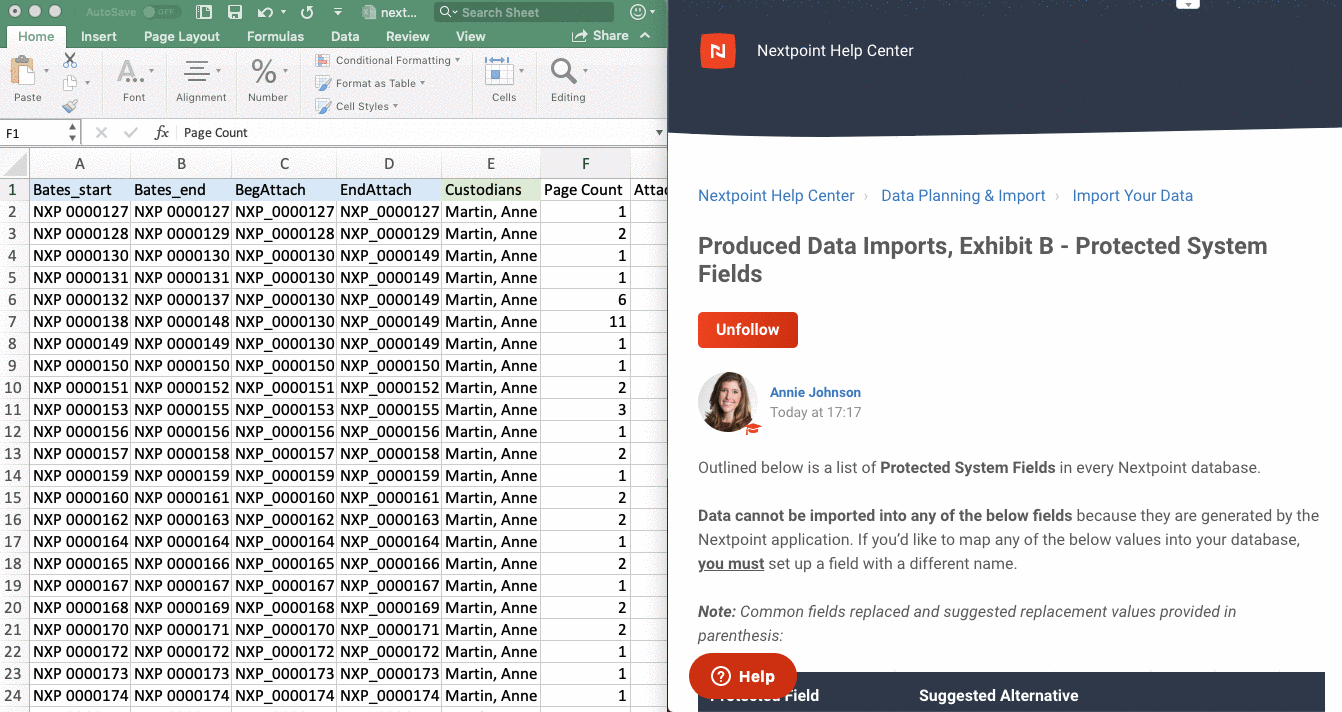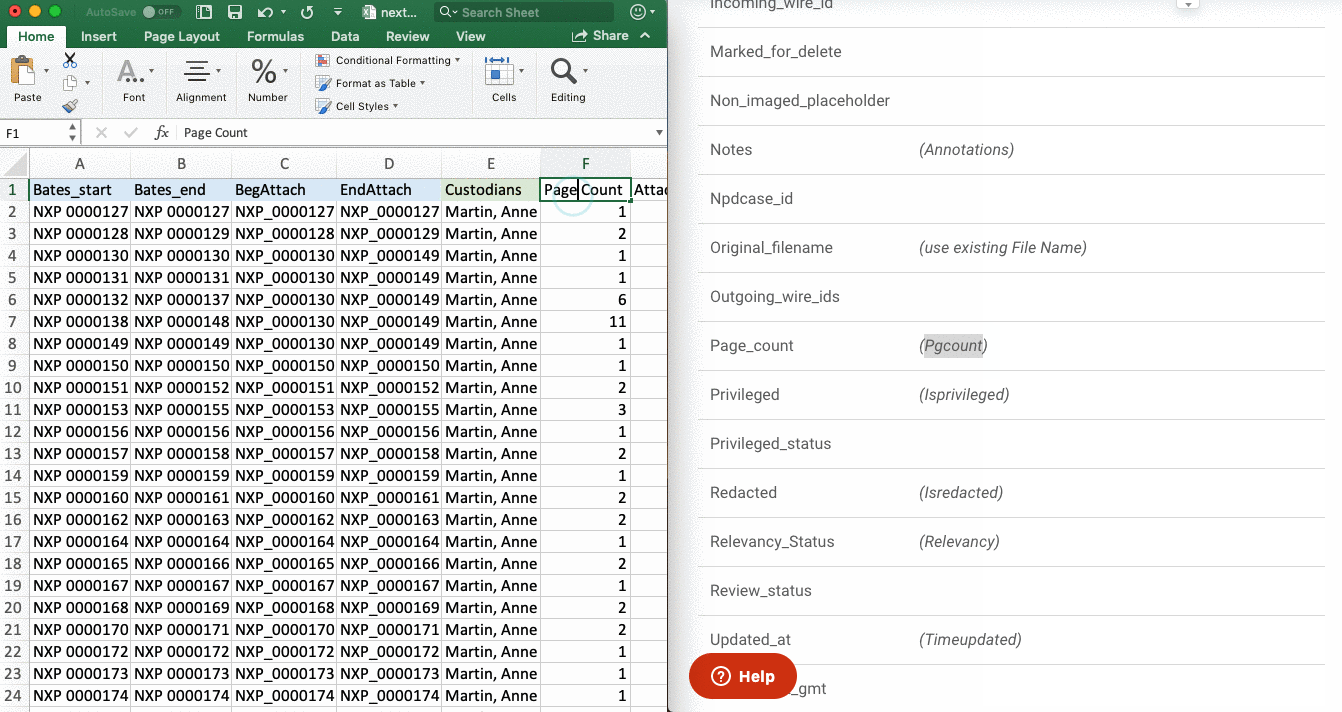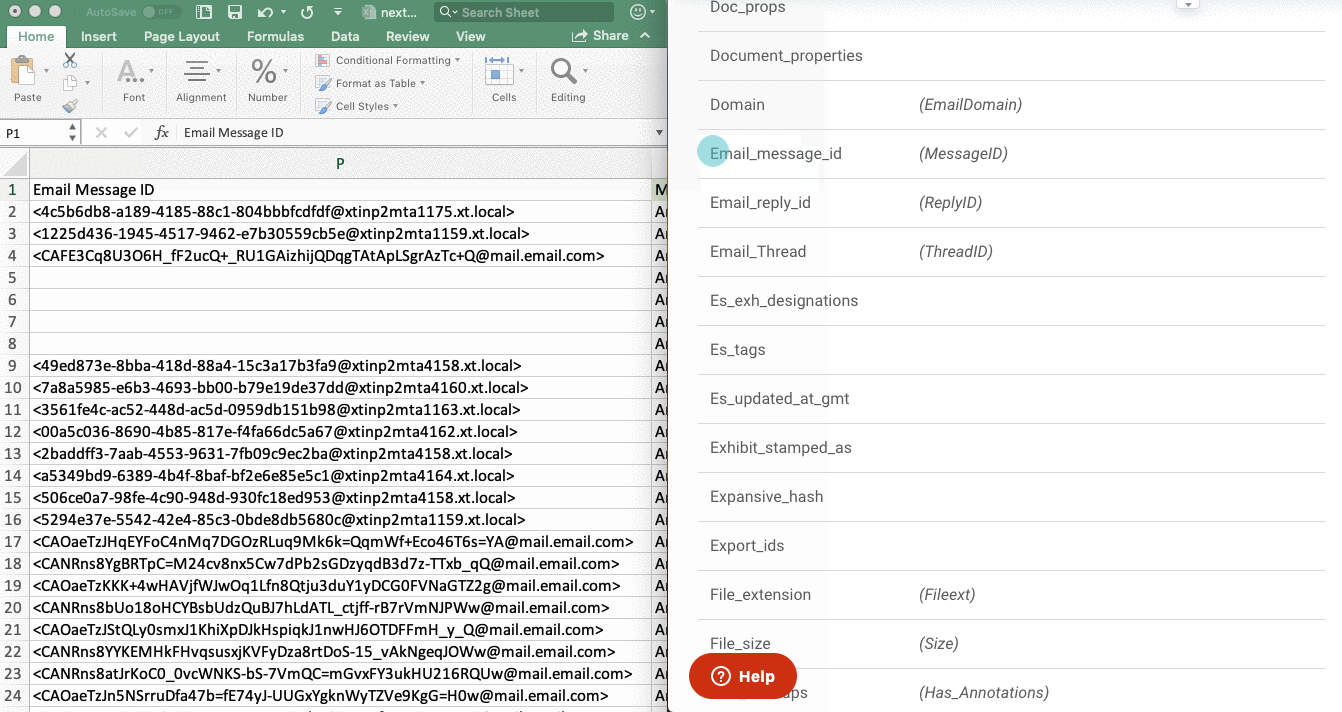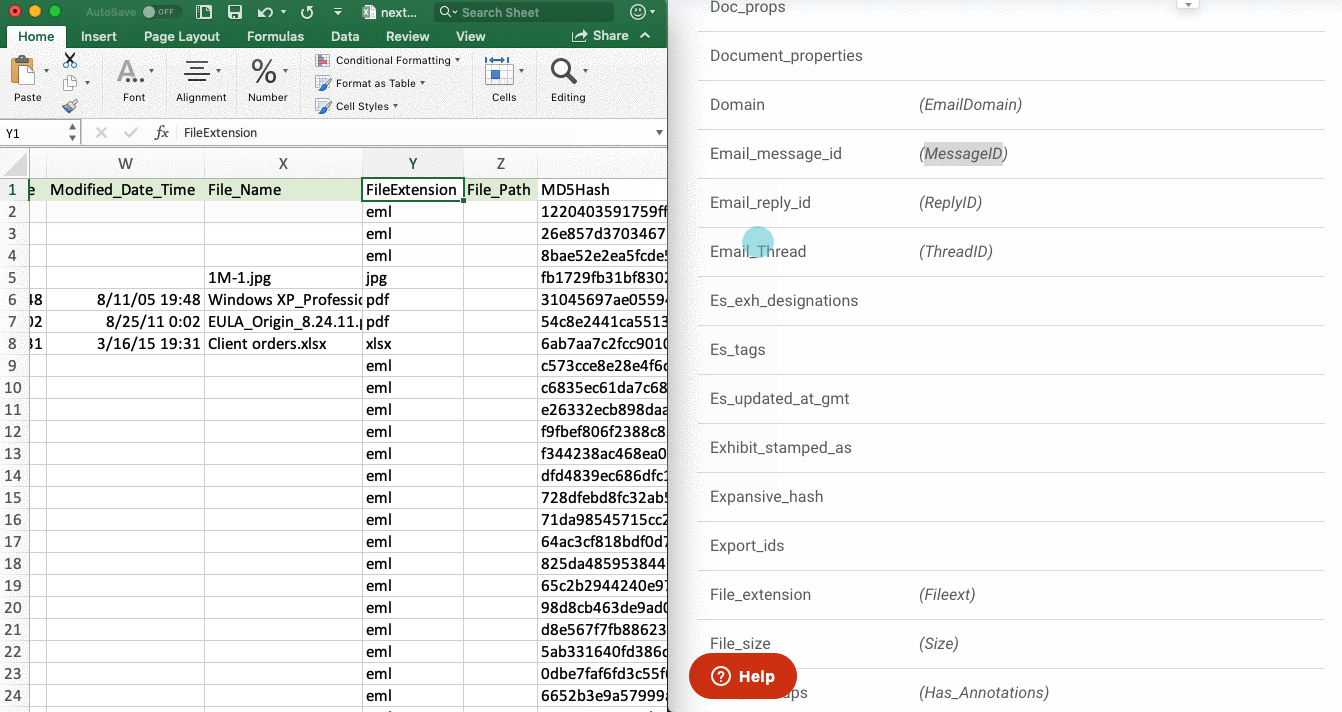
- If you change a column header in your load file (in 2.2 above), you must also set up the corresponding field in your Nextpoint Discovery database by navigating to Settings Coding Fields Create New Select Freeform Field enter the field name click "Create".
- Importing to a Litigation database? You can add these fields under MORE Settings Coding Fields.
- TEXT & NATIVE PATHS
Next up? Text and Native Paths.
During import, Nextpoint needs to know which text and native files to pull from their respective TEXT and NATIVE folders, and line up with their corresponding document image(s) from the IMAGES folder. This is accomplished by using the text_file and/or native_file column headers in your load file, which contain the path to, and name of, the text and native files, respectively.
Oftentimes, you will not be provided with ALL natives, but rather a select set of file types which do not image well (or at all). If you notice your native_file column lacking information in many of the cells, there is likely nothing wrong with your import, and rather only certain file types were provided natively (e.g. Excels, Powerpoints, Autocad drawings, etc).
- In your load file, make sure these two column headers are named text_file and native_file, respectively. They must be named as such in order for the import to work correctly.
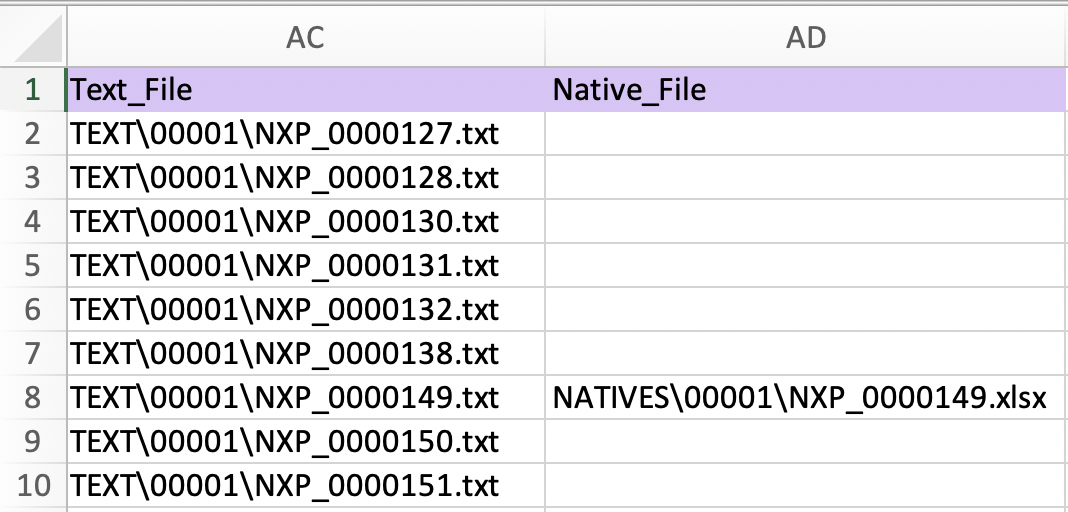
- Then, in your load file, check to make sure the paths are relative to where the load file will be saved. It is critical to your import's success that the nextpoint_load_file.csv includes native and text path information relative to where the load file resides in your production set's base folder.
- The relative path for any native file starts with NATIVES. For example, the first value of the native_file column in the image above is NATIVES\00001\NXP000149.xlsx
- The relative path for any text file starts with TEXT. For example, the first value of the text_file column in the image above is TEXT\00001\NXP_0000127.txt
- See more information on relative paths here.
- In your load file, make sure these two column headers are named text_file and native_file, respectively. They must be named as such in order for the import to work correctly.
- EVERYTHING ELSE
- After addressing the Default Fields, Protected System Fields, and Text/Native Paths above, check for any remaining headers in your load file without a corresponding field in your Nextpoint database.
- If remaining fields are found, create a new Field in your database named exactly the same as your load file header(s).
- Working in a Discovery database? Navigate to Settings Coding Fields Create New Select Freeform Field and enter the field name.
- Working in a Litigation database? Navigate to MORE first, then Settings Coding Fields Create New Select Freeform Field and enter the field name.
After your load file is configured in Step 3, it is critical to the import’s success to save your load file as nextpoint_load_file.csv. This is what indicates to Nextpoint during import "this is a load file and you should use it for this import".
- First, move your load file to the root of your production folder.
- Then, upload your production folder to your Nextpoint File Room by dragging and dropping the unzipped folder.
Initiate the Import Workflow via DATA Import Import Files Select Manual Import.
Once in the guided import workflow, take the following steps:
- Select the Manual Import type in Step 1 of the Import Workflow click Next.
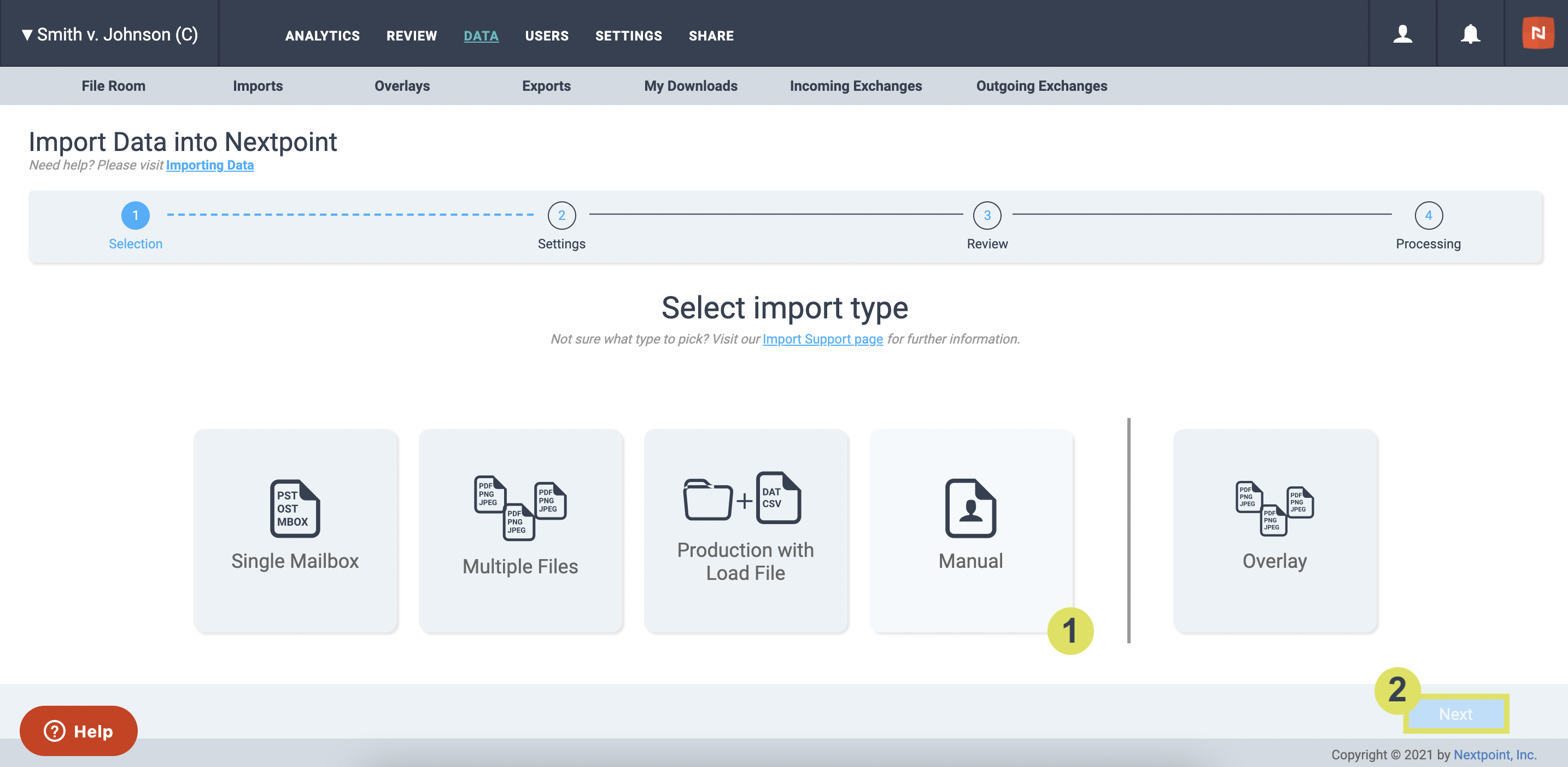
- You will be navigated to Import Data Settings. Here, select your files for import by first clicking on the folder icon next to the Files text.
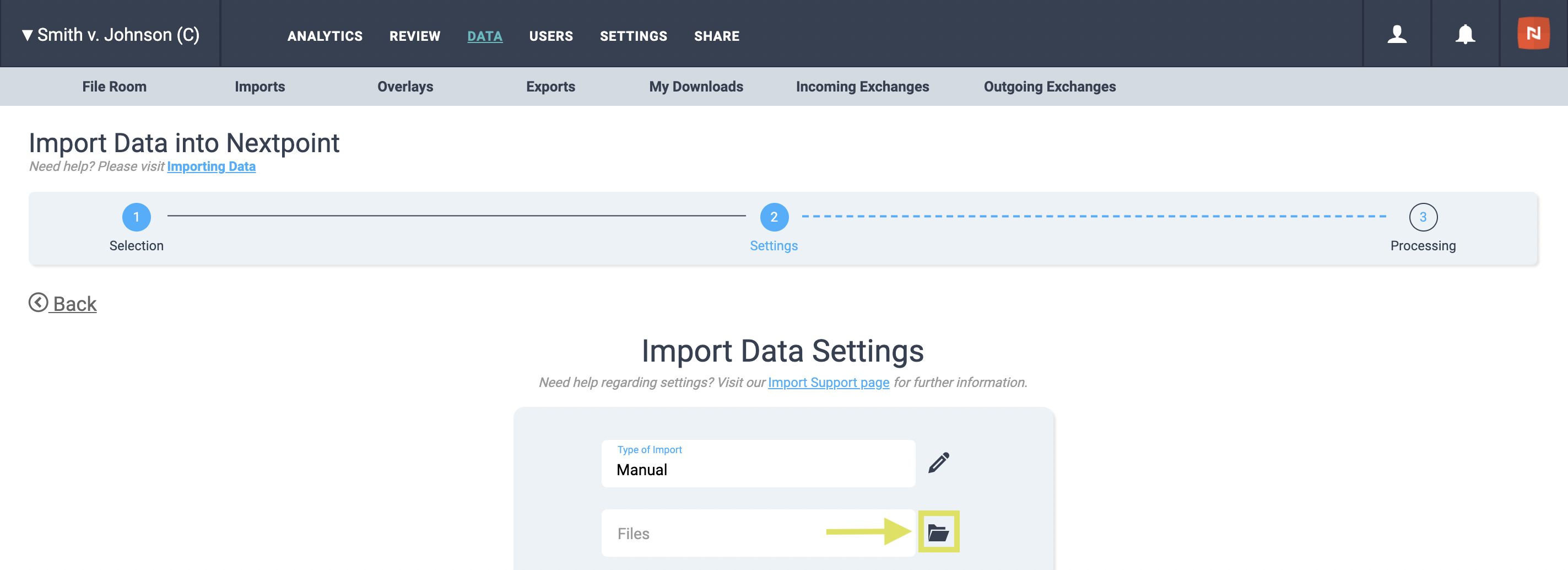
Then, select your parent production folder click orange Add selected to import list button click blue Import button.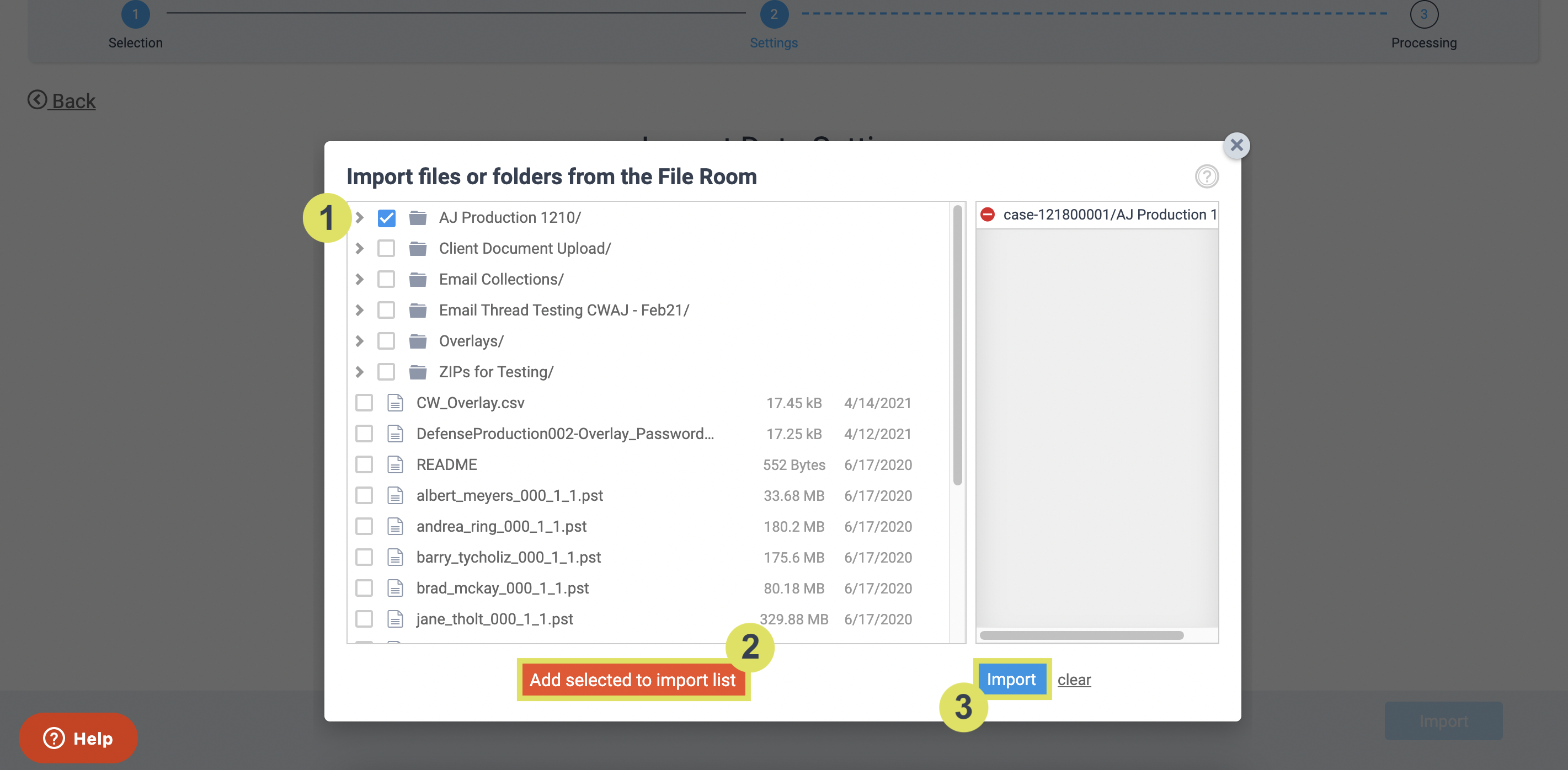
After you've selected your file for import, complete the remainder of the Import Data Settings. This includes naming your import batch, selecting a folder to which you would like your documents added after processing is complete, deduplication settings(we recommend deduplication be off for produced data), and Child Processing settings.
What is Child Processing? When enabled, children of parent emails or contents of zip files will be extracted and process in their standard format as stand-alone documents after import.When disabled, children will not be extracted from their parents. Disabling this feature may be leveraged in use cases such as native production imports with a load file, or in the event that children have been processed separately from the import at hand.
Once the aforementioned settings are determined, click the blue Next button to initiate your import.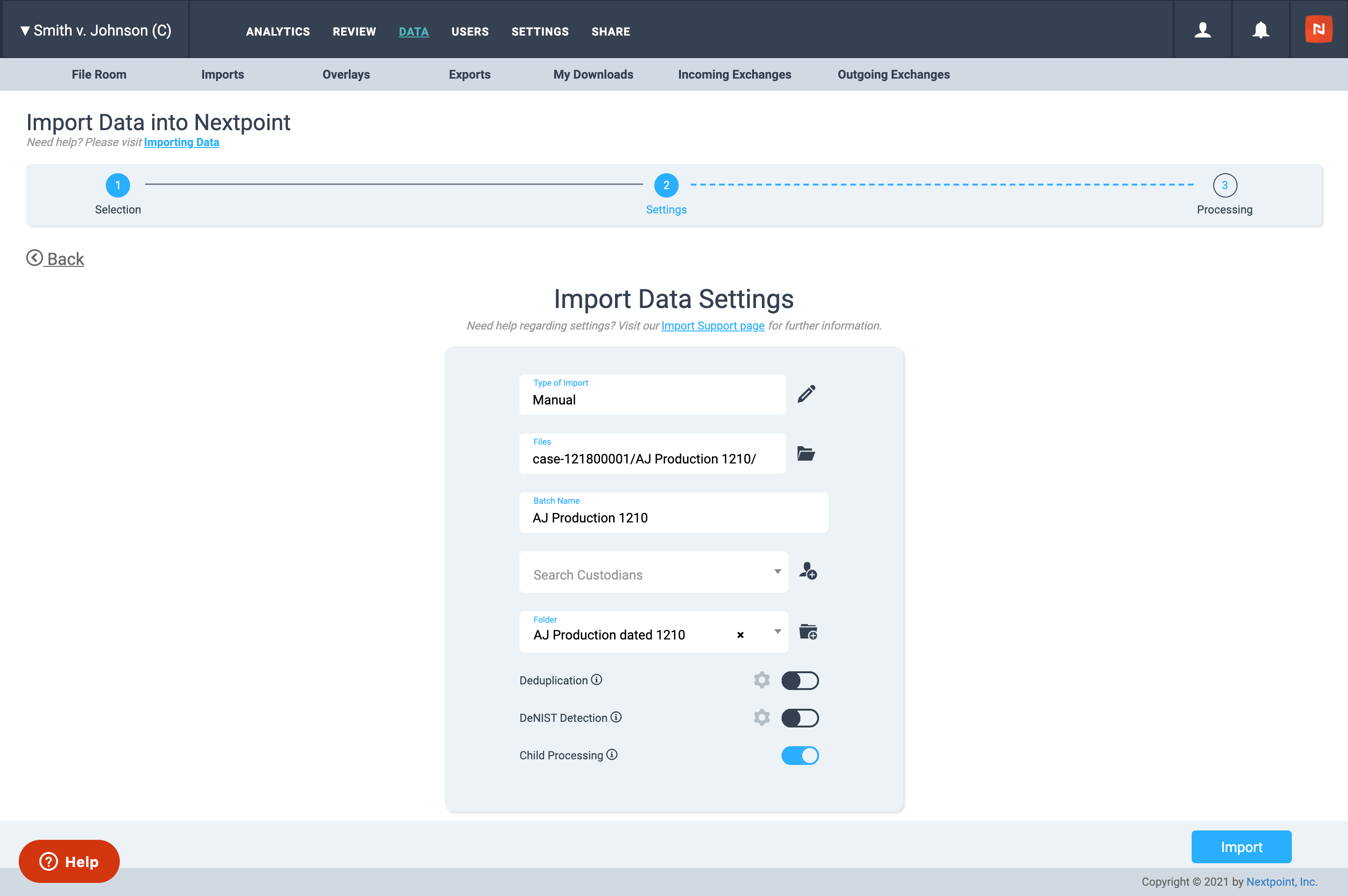
My Import Didn't Work, Why?
Every import is different, and sometimes even the smallest nuance can affect the outcome of your import. We have compiled a list of common import errors and solutions for general troubleshooting, and are further developing more specific troubleshooting options for produced data imports, specifically.
Once your Import is has completed processing, you will receive an email notification, and subsequently run “Family Linking" from your Batch Summary page. This is vital for visually establishing parent-email relationships in your import.
- You will receive an email notification stating your import is Complete. Click on the link contained within the email, or navigate back to Data Imports and click on the title of the batch you just imported to view the Batch Summary. Working in a Litigation database? Navigate here via More Data Imports.
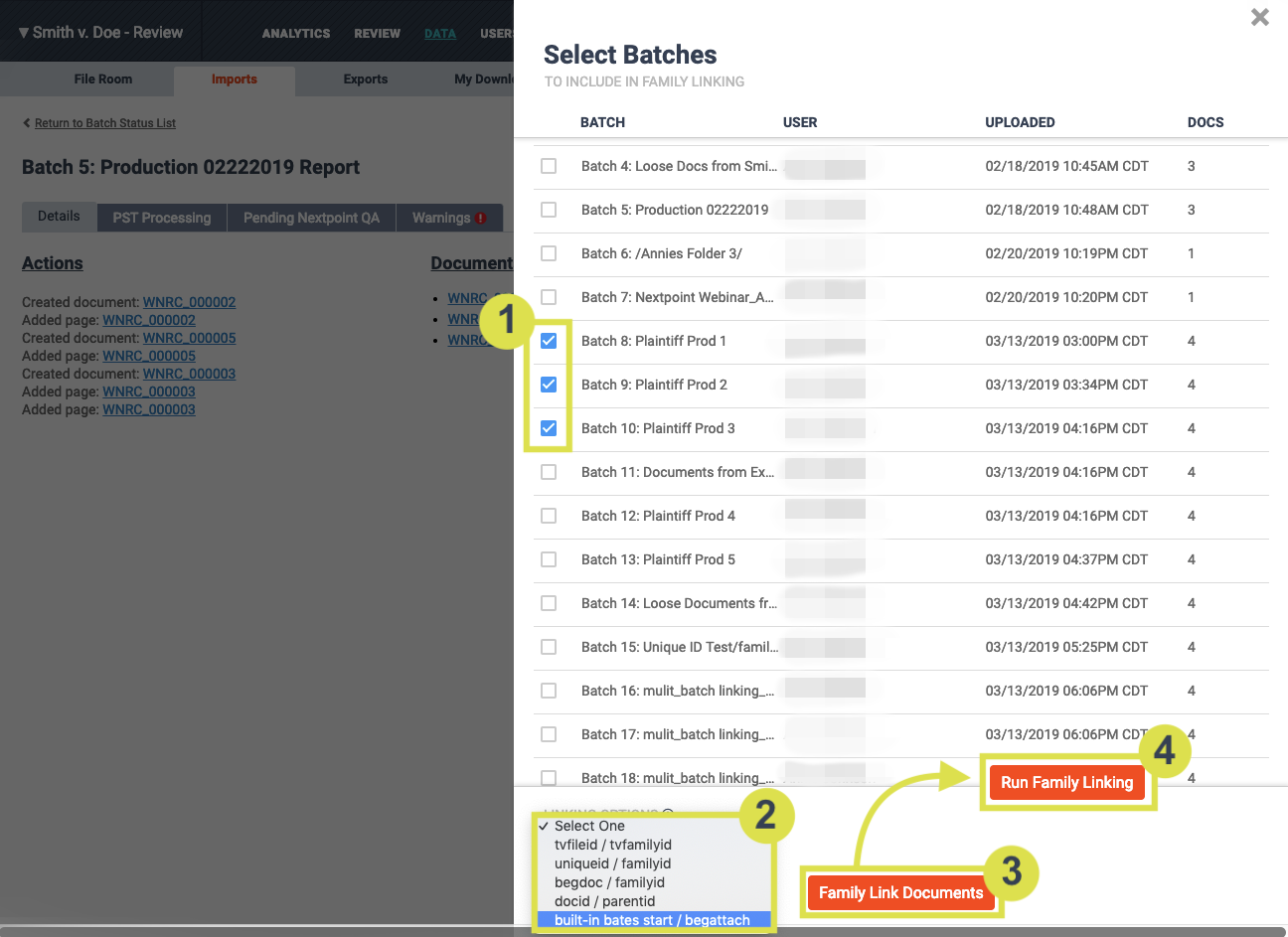
- At the bottom right of your Batch Summary page, click
 . A sliding menu will appear with checkboxes & headers for Batch, User, Uploaded, Docs (batch number, importing user, upload date, batch document count), and a selection drop-down for your Linking Options.
. A sliding menu will appear with checkboxes & headers for Batch, User, Uploaded, Docs (batch number, importing user, upload date, batch document count), and a selection drop-down for your Linking Options.
- Select the batch(es) you would like to Family Link. You can link more than one batch at the same time.
- Select the fields Nextpoint should use to link parent emails to their attachments via the "Linking Options" drop-down. If you utilized Begattach/Endattach in Step 3/Family Relationships, select that option from the drop-down.
- Click "Family Link Documents"
- Confirm your selection by clicking "Run Family Linking"
- Once linking is complete you will receive an email with a link back to the Batch Summary page where you can download and review a report to ensure the emails and attachments were linked without issue.

Have Questions?
Produced data and migration imports can be difficult. After reviewing the above Produced Data Import Approach, if you need additional training or assistance from the Nextpoint Engagement, please contact your Client Success Director or the Nextpoint Support Team.
Default Fields & Document Attributes
For any of the below-listed fields, you do not need to set up a new Field under SETTINGS > Coding. Instead, if you have a header value in Row 1 of your load file, make sure that the load file value matches the below default fields exactly.
Values can be imported by load file headers to the provided values. App Name indicates what your load file header should read. Visible vs. Hidden indicates if a field can be seen under SETTINGS Coding Fields (Visible), or if it isn't seen in the field list but can accept your load file information (Hidden).
| App Name | Visible vs. Hidden |
|---|---|
| Author | Hidden |
| Bates_Start | Hidden |
| Bates_End | Hidden |
| Bates_Range_Start | Hidden |
| Bates_Range_End | Hidden |
| BCC | Visible |
| CC | Visible |
| Created_Date_Time | Visible |
| Custodian | Hidden |
| Custodians | Hidden |
| Date | Hidden |
| Document_Author | Visible |
| Document_Last_Author | Visible |
| Document_Subject | Visible |
| Document_Title | Visible |
| Document_Type | Hidden |
| Document_Date | Hidden |
| Email_Author | Visible |
| Email_Received | Visible |
| Email_Sent | Visible |
| Email_Subject | Visible |
| Email_Thread_Index | Hidden |
| Encrypted | Visible |
| File_Name | Visible |
| File_Path | Visible |
| Image_File | Hidden |
| Image_Range_Start | Hidden |
| Image_Range_End | Hidden |
| Last_Print_Date | Visible |
| Mailbox_File | Visible |
| Mailbox_Path | Visible |
| Modified_Date_Time | Visible |
| Native_File | Hidden |
| Recipients | Visible |
| Root_Folder | Visible |
| Shortcut | Hidden |
| Tags | Hidden |
| Text_File | Hidden |
| Title | Hidden |
Important Field Notes:
- Custodian/Custodians are visible under Settings > Import > Custodians
- Have existing/historical Tags you want to migrate to Nextpoint's Additional Tags field? Your column header should read Tags and the values should be semicolon delimited (e.g. Bob Randolph; hard copy document; Production 1; 10/22/2019).
Protected System Fields
Data cannot be imported into any of the below fields because they are generated by the Nextpoint application.
If you’d like to map any of the below values into your database, you will be required to setup a field with a different name.
Note: Common fields replaced and suggested replacement values provided in parenthesis:
| Protected Field | Suggested Alternative |
|---|---|
| Filename | (use existing File Name) |
| Filepath | (use existing File Path) |
| batch | |
| batch_id | |
| batch_ids | |
| Bates | (use existing Bates_start and Bates_end as applicable) |
| Bates_stamped | |
| Confidentiality | (Conf_Status) |
| Confidentiality_Status | (Conf_Status) |
| Content_hash | (ContentHash) |
| Created_at | (use existing Created_Date_Time) |
| Created_at_gmt | (Created_Date_Time) |
| Created_on | |
| Delete_at_gmt | |
| Deposition_id | |
| Deposition_names | |
| Deposition_volume_id | |
| Display_name | |
| Doc_props | |
| Document_properties | |
| Domain | (EmailDomain) |
| Email_message_id | (MessageID) |
| Email_reply_id | (ReplyID) |
| Email_Thread | (ThreadID) |
| Es_exh_designations | |
| Es_tags | |
| Es_updated_at_gmt | |
| Exhibit_stamped_as | |
| Expansive_hash | |
| Export_ids | |
| File_extension | (Fileext) |
| File_size | (Size) |
| Has_markups | (Has_Annotations) |
| Has_native_placeholder | |
| Highlight_issues | (Annotation_Issues) |
| Highlight_notes | (Annotation_Notes) |
| Id | |
| Incoming_wire_id | |
| Issues | (Document_Issues); (DocIssues) |
| Marked_for_delete | |
| Non_imaged_placeholder | |
| Notes | (Annotations) |
| Npdcase_id | |
| Original_filename | (use existing File Name) |
| Outgoing_wire_ids | |
| Page_count | (Pgcount) |
| Privileged | (Isprivileged) |
| Privileged_status | |
| Redacted | (Isredacted) |
| Relevancy_Status | (Relevancy) |
| Responsive_Issues | (Resp_Issues) |
| Review_status | |
| Updated_at | (Timeupdated) |
| Updated_at_gmt | |
| Updated_on | |
| Verified_page_count | |
| Wire_transfer_tags |
Comments
Please sign in to leave a comment.